
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
国家レベルの安全性と自律型AIの衝突
Anthropicが国家の重要インフラに食い込んだ。
オーストラリア政府とAI安全性研究におけるMOUを締結した。
投資額はAUD300万。
医療診断や精密医療、そして国家の基幹産業にClaudeが直接導入される。
一方で、開発者の足元では大きな変化が起きている。
Claude Codeが完全自律実行機能を手に入れた。
ターミナルからGUIを操作し、AIが勝手にコードを書き、テストを回す。
国家が認める極限の安全性と、開発環境を塗り替えるほどの強大な自律性が同時に進行している。
医療・教育への巨額投資と次世代モデルの足音
Anthropicがオーストラリア政府と公式に提携した。
AIの安全性研究と国家AI計画の推進を目的とした戦略的なMOUの締結だ。
AUD300万の資金が、オーストラリアの主要な研究機関に投じられる。
小児医療、臨床ゲノミクス、精密医療の研究にClaudeのAPIクレジットが提供される。
単なる資金提供のニュースではない。
オーストラリアのAI Safety Instituteとの緊密な連携が中核にある。
次世代モデルの能力と潜在的なリスクに関するデータを、政府と直接共有する。
米国、英国、日本に続く、国家レベルの安全保障ネットワークの構築だ。
Anthropicは経済指標データもオーストラリア政府に提供する。
農業、ヘルスケア、金融サービスなど、重要産業におけるAIの導入状況を追跡する。
労働市場への影響を分析し、国家規模でのAI教育プログラムの開発にも着手する。
AnthropicのEconomic Index dataによると、オーストラリア人はすでに英語圏の中で最も多様なタスクにClaudeを活用している。
同時に、水面下では次世代モデルの情報が流れている。
コードネーム「Capybara」と呼ばれるClaude Mythosの存在がリークされた。
現行の最上位モデルを大幅に凌駕する推論能力を持つとされている。
AIによる自律的な科学的発見を目指すオープンソースプロジェクト「AI-Scientist-v2」も公開された。
そして、開発者向けツールも大きな進化を遂げた。
Claude CodeのCLIから、直接GUIアプリの操作が可能になった。
さらに完全自律実行モードが追加された。
ターミナルでコマンドを叩くだけで、AIが自律的にタスクを進行する。
SNSでは23,000件以上の「いいね」がつき、界隈は騒然としている。
開発者がブラウザを開き、ドキュメントを読み、コードを修正する一連のプロセスを、Claude Codeが完全に代替しようとしている。
国家インフラへの導入と、完全自律型AIの一般解放。
強力すぎるAI能力を社会実装するには、それと同等に強力な安全網が必要だ。
モデルが賢くなればなるほど、入力されるデータの機密性は跳ね上がる。
だからこそ、APIのデータ保持ポリシーや契約形態が今、かつてないほど問われている。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。

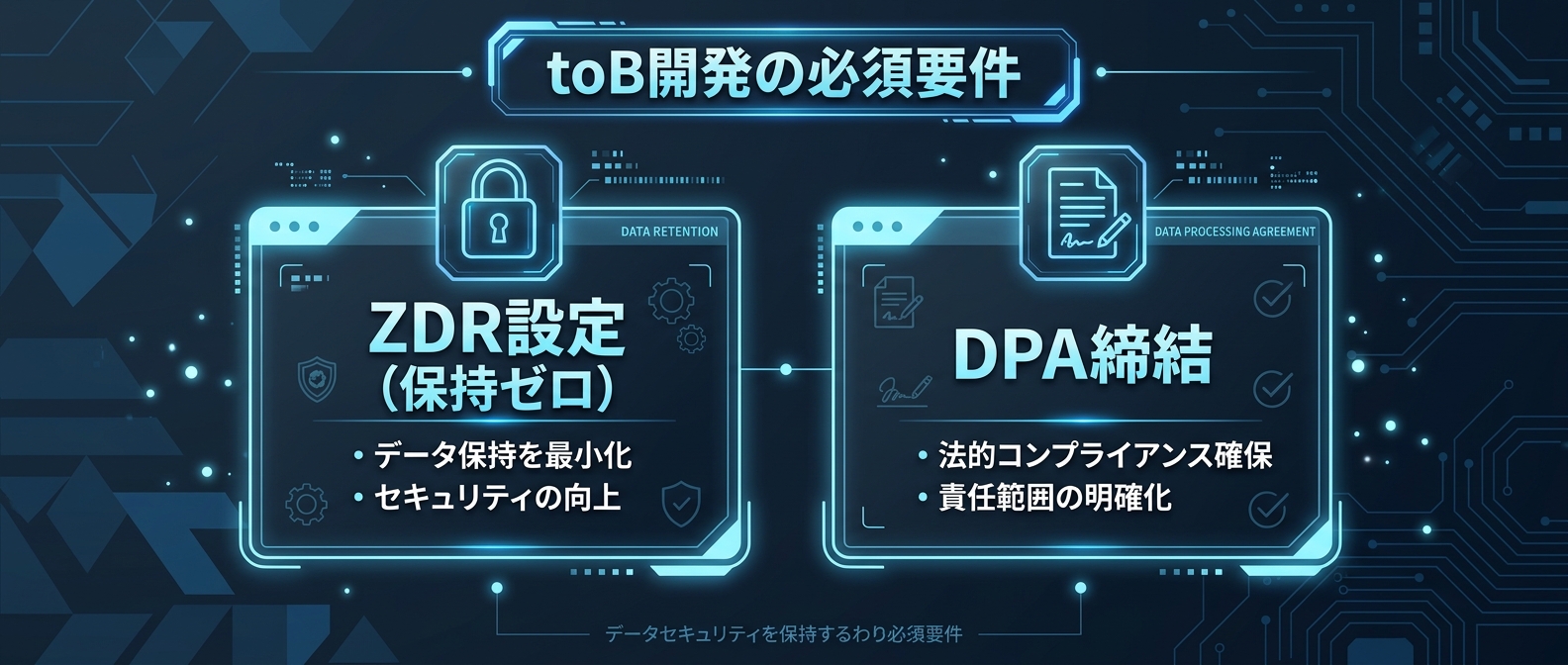
ZDRとDPAが分けるtoB開発の成否
なぜオーストラリア政府は数あるAI企業の中からAnthropicを選んだのか。
「安全性」と「制御可能性」を最優先にアーキテクチャを設計しているからだ。
僕ら開発者にとって、これは対岸の火事ではない。
モデルが自律的にGUIを操作し、科学研究すら行うレベルに到達した。
そんな強大な能力を持つAIを、toB向けのSaaSや社内システムに組み込む。
エンタープライズの顧客からは「自社の機密データはどう扱われるのか」と厳しく問われる。
ここで極めて重要になるのが、ZDRとDPAだ。
API経由で送信されたデータはデフォルトで学習に使われない。
これは2025年以降、主要プロバイダーの共通仕様となった。
しかし「学習に使わない」ことと「データを保持しない」ことは全く別の概念だ。
OpenAI APIでは、不正利用監視を目的としてプロンプトを最大30日間保持する。
これを完全にゼロにするのがZDR設定だ。
しんたろー:
ZDR有効にした瞬間、自前でログ基盤作らないとデバッグできなくなるのキツい。
OpenAI APIはZDR有効だとstoreパラメータが常にfalseになる仕様で、アプリ側でstore: trueを指定しても無視される。
金融機関や医療機関、あるいは国家インフラレベルのシステムを構築する場合、ZDRの有効化は絶対条件になる。
プロバイダー側にデータが残るアーキテクチャは、コンプライアンス審査で確実に弾かれる。
さらに、個人データを扱うならDPAの締結も必須だ。
プロバイダーがどのような技術的・組織的安全管理措置を講じているか、アクセス制御、暗号化基準、インシデント発生時の報告義務を契約として明文化するのがDPAの役割だ。
多くの場合、標準の利用規約ではエンタープライズ要件を満たせない。
上位プランを契約し、個別のDPAを締結する必要がある。
スタートアップであっても、顧客企業の法務部門からDPAの提示を求められるのが現実だ。
DPAの個別交渉はEnterpriseプラン以上でないと困難なケースが多い。
そして、Claude Codeの進化だ。
完全自律実行モードは、僕らの開発体験を根底から覆す。
AIにタスクを投げれば、勝手にブラウザを開き、リファレンスを検索し、コードを書き、テストを回す。
自律性が高まるほど、AIに渡すデータの機密性も跳ね上がる。
ローカル環境のソースコード、環境変数、テスト用のダミーデータ。
これらがAPIを経由してどのように処理されるか、開発者自身がデータフローを完全に把握しておく必要がある。
高度な自律型AIの能力を最大限に引き出すこと。
同時に、エンタープライズ水準の厳格なデータ保護要件を満たすこと。
この2つを両立させるセキュアなアーキテクチャ設計が、これからのtoB開発における競争優位性になる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
コードを書く前に法務要件を実装する
コードを書き始める前に、法務面とデータフローを完全にクリアにする。
後からアーキテクチャを変更するのは致命的なコストになる。
具体的には以下の3点だ。
- APIデータポリシーの確認とZDRの適用
- DPAの締結状況と安全管理措置の把握
- 個人情報保護法上の外国第三者提供の整理
特に3つ目が厄介だ。
toBアプリのプロンプトに顧客の個人データが含まれる場合、日本の個人情報保護法では、海外のLLMプロバイダーへのデータ送信は「外国第三者提供」に該当する可能性が高い。
「単なるクラウドサービスだから委託に該当する」という解釈は通用しない。
LLMはプロンプト内のデータを解析し、推論処理を行って結果を返す。
個人情報保護委員会のQ&Aでは、クラウドサービス提供者がデータを取り扱わない場合のみ「提供」に該当しないとしている。
LLM APIの場合、プロバイダーはプロンプト内のデータを処理するため、単純なクラウドストレージとは異なる判断が必要だ。
クラウド例外規定がLLMに適用されない件、法務から突っ込まれてプロジェクト止まるのよく見る。
後からアーキテクチャ変更とか地獄だから、初期設計の段階で絶対潰しておきたい。
対策は2つに1つだ。
日本国内のリージョンを持つプロバイダーを選定し、データを国内に留めるか、あるいは適切な同意取得と委託先の監督義務を果たす体制を構築するかだ。
2025年2月に経済産業省が公表した「AIの利用・開発に関する契約チェックリスト」も、実務の標準になりつつある。
SLAの定義、生成物の知的財産権の帰属、ハルシネーションによる損害の責任分界点を開発初期段階で法務部門とすり合わせる。
RAGやファインチューニングを実装する場合はさらに複雑だ。
ベクトルデータベースに格納するドキュメントのアクセス権限、学習データに個人情報が混入するリスクの排除をシステム的に担保しなければならない。
Claude Codeを使って爆速でプロトタイプを作るのはいい。
完全自律実行モードで、テストもデプロイも自動化できる。
だが、本番環境にデプロイする前に、データの流れを完全に制御する。
- エンドポイントごとのオプトアウト設定を明示的に行う
- 送信前のプロンプトから個人情報を除去するマスキング処理を実装する
- ZDR環境下での独自監視基盤と監査ログの仕組みを構築する
- APIキーの権限スコープを最小限に絞り込む
- ローカル環境の機密情報がプロンプトに混入しないようフィルタリングする
これらをアーキテクチャの根幹に組み込む。

Claude Codeの完全自律モード、裏でどんなコマンド叩いてるか監視しないと普通に怖い。
権限管理はガチガチにしないと事故る。
FAQ
toBアプリでAPIを使う際、データは学習に使われますか?
API経由で送信されたデータは、デフォルトでモデルの学習には利用されない。
Anthropicを含む主要プロバイダー共通の仕様となっている。
ただし、データの保持期間はプロバイダーごとに異なる。
OpenAI APIでは不正利用監視のために最大30日間保持されるケースもある。
エンタープライズ用途では、データ保持を完全にゼロにするZDRの設定が必須だ。
消費者向けインターフェースの利用規約と、APIの利用規約は明確に区別してアーキテクチャを設計する。
日本の個人情報保護法において、海外のLLM APIを使う際の注意点は?
プロンプトに顧客の個人データが含まれる場合、「外国第三者提供」に該当する可能性が高い。
LLMは入力データを内部で処理・推論するため、単なるデータ保管を目的としたクラウドサービスの例外規定は適用されない。
法第28条に基づく適切な対応が求められる。
具体的には、本人の事前同意を取得するか、個人情報保護委員会が認める基準に適合する体制を整備した事業者に委託する形をとる。
開発段階から法務部門と連携し、データの流れを可視化するアーキテクチャ設計が前提となる。
Claude Codeの「完全自律実行」とはどのような機能ですか?
ターミナル上で特定のフラグを付与することで、Claudeが自律的にタスクを進行する機能だ。
開発者の介入なしに、コードの記述、ファイルの編集、テストの実行、さらにはGUIアプリの操作までを連続して行う。
エージェント型AIの進化系であり、推論と行動のループを自動で回す。
開発効率は向上するが、同時にローカル環境へのアクセス権限をAIに委ねることになる。
実行環境のサンドボックス化や、機密情報の環境変数管理など、セキュリティを前提とした開発フローの構築が前提となる。
自律型AI時代の開発基盤を築く
国家レベルのAI導入と、自律型エージェントの進化は、僕らのシステム設計に全く新しい基準を要求している。
高度な自律型AIを組み込んだtoBアプリ開発の知見も、ThreadPostで効率的に発信・共有しましょう。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
