
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
CLAUDE.mdが200行を超えたとき、AIは壊れ始める
CLAUDE.mdにルールを追加し続けたら、AIがルールを守れなくなった。
これはバグじゃない。設計上の必然だ。
ルールが20〜30個を超えると、AIの認知負荷が限界を超える。
判断力が本来の仕事ではなくルール同士の交通整理に消費され始める。
解決策は3つある。
Git worktreeによる作業空間の物理的隔離とHooksやSkillsによる機能のモジュール化だ。
さらに因果の連鎖を記述するプロンプト設計を加える。
この3つを組み合わせることで、AIは迷わず動ける。
AIがルール違反を起こす構造的な理由
CLAUDE.mdは、Claude Codeが起動するたびに最初に読み込む設定ファイルだ。
ここに書かれたことがセッション全体の判断基準になる。
仕組みとしては正しい。
テストはpytestを使えと書けばunittestは選ばない。
importはnamed importで統一とあればdefault exportは作らない。
一対一対応のルールは確実に効く。
問題はスケールだ。
AIが間違えるたびにルールを追加する。
失敗から原因分析を経てルールを追加し、再発防止につなげるサイクルは機能する。
人間のポストモーテムと違って、書いたルールは100%の確率で次のセッションに読み込まれる。
ルールが増えると矛盾が生まれる。
Slackに投稿する前に重複チェックをせよというルールと、Slackへの応答は1分以内にせよというルールが同居した事例がある。
重複チェックにはAPI呼び出しが必要で数秒かかる。
1分以内に応答しようとすると重複チェックを省きたくなる。
人間なら今回は重複チェック優先と片方を捨てる判断ができる。
AIは毎回律儀に両方を遵守しようとして、認知負荷の限界を超える。
結果として重複チェックが甘いまま急いで投稿して、同じ内容を2回投稿した。
ルールが増えるほどこの種の衝突は増える。
ガイドがノイズになる瞬間だ。
もう一つの問題はWhy不在のルールだ。
パフォーマンスより可読性を優先とだけ書いてある場合、AIは適用範囲がわからない。
10行のユーティリティ関数ならどちらでも同じだ。
毎秒10万リクエストが通るホットパスなら可読性を犠牲にする場面もある。
AIはなぜこのルールがあるのかを知らないから、境界的なケースで迷う。
しんたろー:
うちの構成もそうなっているかもしれないと気になった。
CLAUDE.mdに追記を繰り返していると、いつの間にかルールが矛盾している。
AIが変な動きをするとき、モデルの問題ではなくCLAUDE.mdの設計の問題だったりする。
ちなみに昨日もルール衝突でAIが無限ループに入り、API代を3ドル溶かした。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
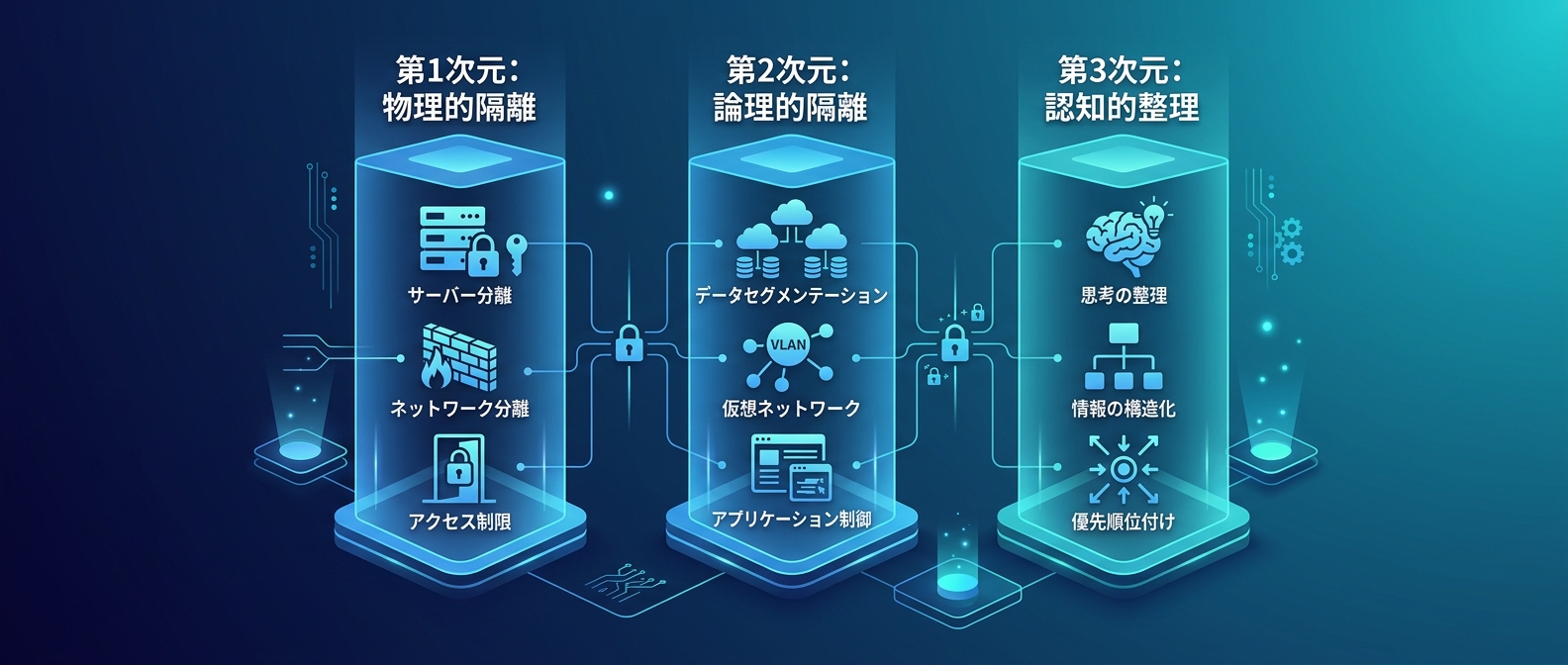
3次元のコンテキスト管理が必要な理由
AIエージェントを本格運用するには、3つの次元でコンテキストを管理する。
第1次元:物理的隔離(Git worktree)
並列開発や複数タスクの同時進行では、作業コンテキストをディレクトリ単位で隔離する。
Git worktreeを使うと、同一リポジトリの複数ブランチを別ディレクトリで同時に開ける。
AIエージェントが異なるタスクで互いの変更を踏み荒らさない。
Claude Codeには--worktreeフラグが用意されている。
これを使うとworktreeを作成してその中でclaudeのプロセスを実行できる。
ディレクトリは自動的に.claude/worktrees/以下に作られる。
変更なしでセッションを終了するとworktreeとブランチが自動削除される。
変更ありで終了すると残すか削除するかを確認してくれる。
クリーンアップの挙動がよく設計されている。
さらに一歩進めると、AIエージェントが自律的にworktreeを作成・削除できる構成にできる。
カスタムスキルとしてgit-wtを定義する。
CLAUDE.mdに軽微な修正以外の実装はgit-wtスキルを利用してworktreeで作業すると記述する。
これでAIが実装の単位で自律的にworktreeを管理する。
第2次元:機能の論理的隔離(Hooks/Skills)
すべての指示をCLAUDE.mdに書くのではなく、適用ロジックをスクリプト側に逃がす。
これがモジュール化の考え方だ。
具体的には、Claude Code向けのコマンドやエージェント、Skills、Hooksを体系的に管理する構成をとる。
Skillsは再利用可能な知識の単位だ。
コマンドやエージェントの文脈に応じて参照され、手順と品質基準を補強する。
HooksはPreToolUseやPostToolUseなどのタイミングで発火する。
品質ゲートや監査ログ、安全チェックを挟む。
この構成の肝は適用ロジックをスクリプト側に集約し、必要な文脈でのみSkillsを参照させる点だ。
CLAUDE.mdにすべてを書くのではなく、必要なものだけを選んで導入できる。
大量のMarkdownベース資産を持ちながら、CLAUDE.md自体はスリムに保てる。
注意点として、SubAgentのYAMLフロントマターでisolationパラメータにworktreeを設定している場合は、Claude Code組み込みのworktree作成が実行される。
そのためworktreeの保存先はシステム固定となる。
git-wtスキル利用による作業ディレクトリの一貫性と、手順の簡素化のどちらを優先するかはトレードオフだ。
第3次元:認知的整理(因果の連鎖の記述)
CLAUDE.mdに書くのはルールではなく因果の連鎖だ。
ルールだけの記述はconsole.logをコミットするなとなる。
因果の連鎖の記述は、本番ログにデバッグ出力が混入して障害になったためconsole.logをコミットするな、デバッグ時はlogger.debugを使うとなる。
Whyは一行で済む。
詳細なインシデント報告を書く必要はない。
大事なのはなぜダメなのかの因果が残っていることだ。
この一行があるだけで、ルールの射程が変わる。
本番ログへの混入が問題という原因がわかっていれば、console.log以外の場面でも同じ判断ができる。
本番環境にデバッグ用の痕跡を残さないという一般原則として機能する。
因果のないルールは応用が効かない。
因果のあるルールは書いていない場面にも効く。
因果の連鎖の話は気になった。
ルールを書くとき何をするなだけ書いていた。
なぜダメかを1行足すだけでAIの判断が変わるなら、見直してみる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
実務への影響:今の構成で何を変えるか
CLAUDE.mdの棚卸しから始める
ルールが20〜30個を超えていたら整理のサインだ。
このルールとあのルールが矛盾する場面はないかを確認する。
ルールを足すより、既存ルールの整合性を確認する方が効果が高い。
具体的な確認ポイントは3つある。
速度と品質チェックが同居していないか。
ファイル読み込みを減らせと毎回確認せよが衝突していないか。
特定のツールを使えと避けろが同じ対象を指していないか。
ルールの書き方を変える
既存のルールをすべて因果の連鎖形式に書き直す。
何々するなだけのルールには必ず理由と代替手段を追記する。
これでルールの総数を増やさずに適用範囲を広げられる。
Hooksで強制できるものはHooksに逃がす
CLAUDE.mdに書いているルールの中でAIが判断する必要がないものはHooksに移す。
例えばコミット前のリント実行やセッション開始時の環境チェックなどはスクリプト側で強制できる。
AIの認知資源を判断が必要な仕事に集中させる。
Git worktreeを並列作業の標準にする
複数タスクを並行して進める場合、worktreeなしで同一ブランチで作業するのはリスクが高い。
Claude Codeの-wフラグを使うか、カスタムスキルとしてgit-wtを定義して自律的に管理させる構成が安定する。
worktreeを使う際の注意点は3つある。
.claude/worktrees/をgitignoreのグローバル設定で除外する。
.envなどの環境変数ファイルは明示的にコピー設定が必要になる。
.worktreeincludeファイルでコピー対象を明示しておく。
SkillsやCommandsの体系化を検討する
繰り返し使う作業フローをSkillsとして定義し、CLAUDE.mdではなくコマンド経由で参照させる構成にする。
CLAUDE.mdはスリムに保ちながら、プロンプト資産は別で管理できる。
worktreeの変更なしで終了したら自動削除の挙動は気になった。
手動でブランチを消し忘れてリポジトリが散らかるのはよくある。
AIが自律的にworktreeを作って消してくれるなら、ブランチ管理の認知コストが下がる。
よくある質問
Q. Claude Codeで並列作業を行う際、環境変数ファイルはどう引き継げばよいですか?
Git worktreeを使う場合、gitignoreに定義されたファイルはデフォルトで新しいworktreeにコピーされない。
環境変数ファイルを引き継ぐには2つの方法がある。
1つ目はwt.copy設定でコピー対象を個別指定する方法だ。
2つ目は.worktreeincludeファイルを作成してコピー対象を明示する方法だ。
Claude Code Desktop版ではすでに対応済みで、CLI版への適用も近日対応予定となっている。
今から.worktreeincludeを作成しておくのが良い。
wt.copyignoredでgitignore対象をすべてコピーすることもできる。
その場合は不要なものをwt.nocopyで除外する。
コピー対象を明示する方が管理しやすい。
Q. CLAUDE.mdにルールを追加し続けるとどうなりますか?
ルールが20〜30個を超えると、ルール同士の矛盾や衝突が発生しやすくなる。
AIはすべてのルールを律儀に遵守しようとする。
認知負荷が限界を超え、重要なルールを守れなくなる。
不要なAPI呼び出しを繰り返すリスクも上がる。
具体的には速度優先のルールと品質チェックのルールが同居したとき、AIは毎回両方を遵守しようとして判断が詰まる。
人間なら状況に応じて片方を捨てられるが、AIはそれが苦手だ。
対処法は2つある。
ルールが増えたら定期的にこのルールとあのルールが矛盾する場面はないかを確認して整理する。
もう1つは、適用ロジックをHooksやスクリプト側に移してCLAUDE.mdに書く量を減らすことだ。
Q. CLAUDE.mdの肥大化を防ぎつつ、AIに適切な指示を出すにはどうすればよいですか?
2つのアプローチが有効だ。
1つ目は因果の連鎖形式で書くことだ。
何々するなだけのルールに理由と代替手段を1行足す。
これにより少ない記述で広いケースに応用が効く。
AIはなぜダメなのかの因果を知ることで、明示されていない場面でも一貫した判断ができる。
2つ目は機能のモジュール化だ。
すべての指示をCLAUDE.mdに書くのではなく、カスタムSkillsやHooksを使って適用ロジックをスクリプト側に逃がす。
繰り返し使う作業フローはSkillsとして定義し、必要な文脈でのみ参照させる。
CLAUDE.mdはスリムに保ちながら、プロンプト資産は別で体系管理できる。
この2つを組み合わせると、CLAUDE.mdの行数を増やさずにAIの判断精度を上げられる。
まとめ
AIがルール違反を起こすとき、モデルの問題ではないことが多い。
CLAUDE.mdの設計の問題だ。
物理的隔離と論理的隔離、認知的整理の3つを組み合わせると、AIは迷わず動ける。
プロンプトを書くスキルだけでなく、AIが動ける環境を設計するスキルが求められている。
Claude Codeで開発するなら、CLAUDE.mdの棚卸しとworktreeの導入を進める。
SNS投稿の管理も、AIに任せる部分が増えてきた。ThreadPostはClaude Codeで作ってる1人SaaSで、SNS運用の自動化を手伝ってくれる。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
