
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
ノートが散らかる問題に、グラフDBで殴り込む
エンジニアのメモは必ず散らかる。Notion、Obsidian、ローカルのMarkdown、Slackの自分用チャンネル。書く場所は増えるのに、「あのとき調べたこと、どこに書いたっけ?」と探す時間だけが積み重なっていく。
注目されているのが、Claude CodeとNeo4j(グラフDB)を組み合わせたローカルGraphRAGシステムだ。APIコストをゼロに近づけながら、使うほど賢くなる知識ベースを自分のマシンで育てる。その構造が、開発者コミュニティで急速に広まっている。
Claude CodeがNeo4jと繋がると何が起きるか
仕組みの全体像
今、開発者の間で広まっているアーキテクチャを整理する。
コアとなる構成はシンプルだ。
- Claude Code — エンティティ抽出・ファイル操作を担う中核エージェント
- Neo4j — 知識をノードとエッジで管理するグラフDB
- BGE-M3などの埋め込みモデル — テキストをベクトル化してセマンティック検索を実現
- ChromaDBなどのベクトルストア — ベクトル検索の受け皿
この4つを組み合わせると、ベクトル検索とグラフトラバーサルのハイブリッド検索が動く。
GraphRAGの何が違うのか
通常のRAGはシンプルだ。テキストをベクトル化して、クエリと類似度が高いチャンクを引っ張ってくる。それをLLMに渡して回答させる。
GraphRAGはここに「関係性」を加える。
たとえば「マイクロサービスアーキテクチャの選定基準」で検索すると、ベクトル的に近いチャンクだけでなく、グラフ上で繋がっているエンティティも一緒に引っ張れる。「Kubernetes」「Docker」「Team Independence」——これらが「どう関係しているか」という文脈ごと取得できる。
複数ドキュメントをまたいだ多段推論が、ここで初めて可能になる。
エンティティ抽出にClaude Code自体を使う設計
今回の実装で特に注目したいのが、エンティティ抽出の部分だ。
GraphRAGを構築するとき、ドキュメントから人物・組織・技術・概念などのエンティティを抽出する工程が必要になる。通常はOpenAIのAPIやAnthropicのAPIを呼び出す。当然、APIキーの管理とトークンコストが発生する。
この実装では違う。Claude Code自体がドキュメントを読んでエンティティを抽出する。
外部APIコールは不要。Claude Codeのスキル(「/ingest」「/graph-search」「/add-knowledge」など)を実行すると、Claudeがローカルのファイルを読み込み、エンティティと関係性を抽出し、Neo4jに保存する。この一連の流れが、外部への通信なしに完結する。
APIコストの削減とセキュリティの確保が、同時に解決される。
しんたろー:
これ見て「あ、そういう使い方か」と思った。Claude Codeって「コードを書くツール」として使ってたけど、ローカルのファイルを読んでエンティティ抽出してDBに書き込む、みたいな「エージェントとしての動き」が普通にできるんだよな。ThreadPostの開発ログとか、調査メモとか、全部ローカルに溜まってるから、これ使ったら「あのとき調べた実装、なんだっけ」問題が解決しそうで気になってる。まあ、まず自分のメモを整理する気力が先に必要なんだけど。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。

開発者目線で見ると、2つのアプローチが面白い
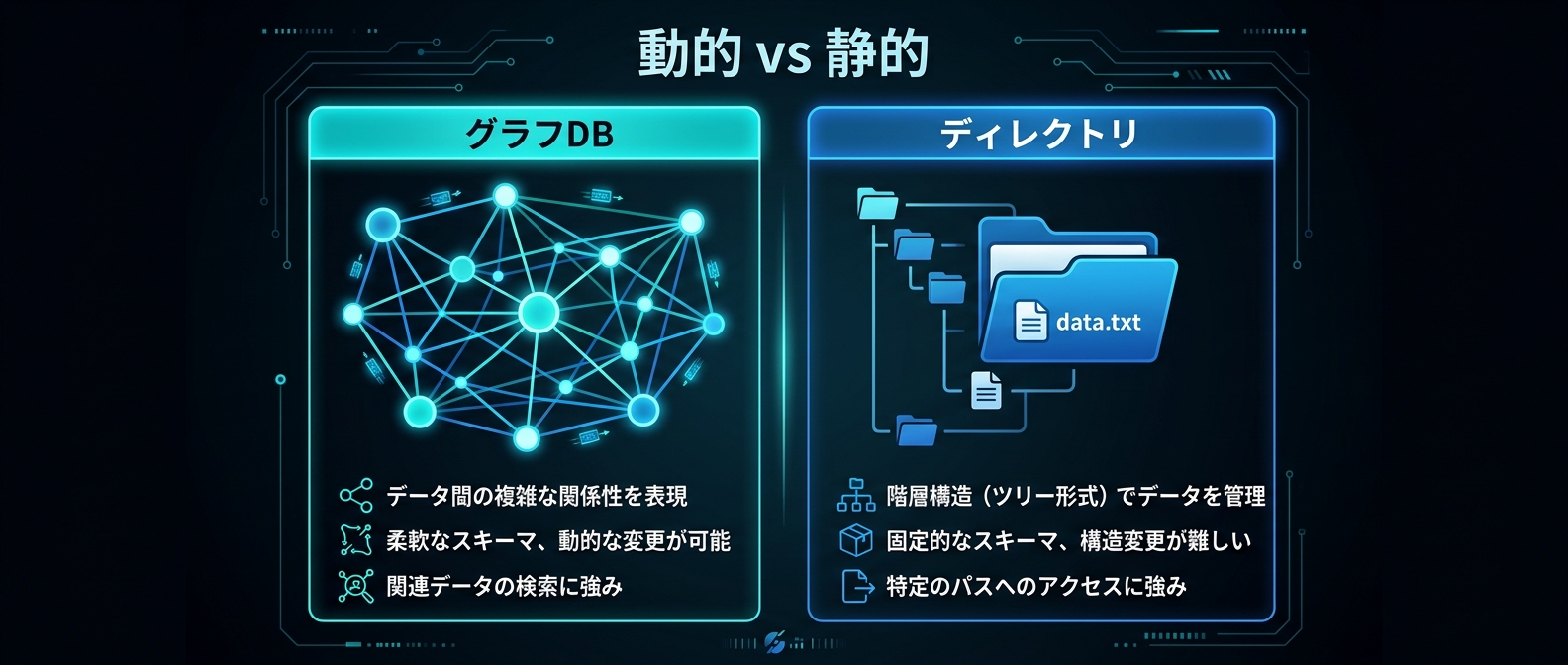
アプローチA — グラフDBで動的に関係性を構築する
Neo4jを使ったGraphRAGは、知識の関係性を自動的に構築する方向性だ。
ドキュメントを投入するたびに、エンティティが増え、エッジが張られ、コミュニティが再構築される。「使うほど賢くなる」という表現が正確に当てはまる。
ソースのタイプも分けられる。PDFから来た知識、URLから来た知識、会話から来た知識——それぞれを別のノードタイプとして管理できる。「この知識はどこから来たか」が即座に判別できるため、信頼度の評価にも使える。
Neo4jはスキーマレスなので、新しいソース種類を後から自由に追加できる。この柔軟性が、個人の知識管理システムとして長期運用するときに効いてくる。
アプローチB — ディレクトリ構造とCLAUDE.mdでルールベースに整理する
もう一つの方向性は、静的なルールで整理するアプローチだ。
自分の活動を「仮想会社」に見立てて、ディレクトリを部署として設計する。「secretary(秘書室)」「pm(プロジェクト管理)」「research(調査)」「engineering(技術設計)」——それぞれのディレクトリにCLAUDE.mdを置いて、その部署の役割とルールを定義する。
Claude Codeがそのルールを読み込んで動くため、「このタスクはどこに入れるか」を毎回考える必要がなくなる。「秘書、これやっておいて」と話しかけると、適切なディレクトリにファイルが作られる。
MCPを使えばObsidianとも連携できる。「作業ログはcompanyディレクトリ、ナレッジはObsidian」と役割を分けることで、どちらも散らかりにくくなる設計だ。
2つのアプローチの違いと使い分け
| | グラフDB(Neo4j)アプローチ | ディレクトリ(CLAUDE.md)アプローチ |
|---|---|---|
| 関係性の構築 | 自動・動的 | 手動・静的 |
| セットアップコスト | 高め | 低め |
| 長期的な賢さ | 育つ | 固定 |
| 技術的難易度 | 高い | 低い |
どちらが「正解」ではない。Neo4jアプローチは「知識が育つ」、ディレクトリアプローチは「すぐ動く」。規模感と目的で選ぶ話だ。
ローカルLLMの現実解 — VRAM 8GBでどこまでできるか
完全ローカル化を目指すなら、LLMもローカルで動かす必要がある。
RTX 4060(VRAM 8GB)という、決してハイエンドではない環境での実装例が参考になる。
- 埋め込みモデル: BGE-M3(多言語対応、8192トークン、VRAM約2.5GB消費)
- LLM: Qwen2.5-32Bをllama.cppで量子化して動作
BGE-M3の選定理由が明確だ。日本語クエリで英語論文を検索するクロスリンガル検索の精度が、他のモデルと比較して明らかに高い。100言語以上に対応している点も、日本語で開発している身には重要だ。
ただし注意点がある。VRAMのピーク消費が約2.5GB。LLMと同時に動かすと、8GBの箱の中でのやりくりが必要になる。バッチ処理のタイミングをずらすか、量子化レベルを調整するか、設計段階で考慮が必要だ。
VRAM 8GBで32Bモデルを量子化して動かす、というのは正直「そこまでやるか」という感想だった。でも動機が「セキュリティポリシーで外部APIに投げられなくなった」というのは、企業の開発者なら全員共感するやつ。APIに投げていいのかどうか、上司に確認するの面倒くさいし、そもそも確認したらダメって言われる未来が見えてる。ローカルで完結する選択肢があるなら、最初からそっちで設計したほうが後が楽だよな、という気持ちはある。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
実務への影響 — 「外部API依存」から「ローカル自律」へのシフト
今すぐ知っておくべき3つの変化
1. Claude Codeの役割が変わってきている
「コードを書くアシスタント」から「ローカル環境を操作する自律エージェント」へ。ファイルを読む、DBに書く、エンティティを抽出する——これらがClaude Codeのスキルとして定義できる。コーディング支援だけで使っているなら、その使い方はまだ表面しか触れていない。
2. 情報の構造化なしに「育つAI」は作れない
グラフ構造(Neo4j)でもディレクトリ設計(CLAUDE.md)でも、どちらも「情報の関係性をどう定義するか」を人間が設計している。AIに任せる前に、情報のルール設計が先に来る。
3. APIコストとセキュリティが、ローカルAI構築を後押ししている
50本の論文を外部APIで処理しようとして「セキュリティポリシー的にダメ」と止まる——これは今後もっと増える。企業での開発なら特に、外部APIに依存しないローカル構成の設計スキルが求められる場面が増えていく。
具体的に何から始めるか
すぐに動かせる順番で整理する。
- 今日できること: Claude Codeのプロジェクトに「.company」ディレクトリを作り、CLAUDE.mdでルールを定義する。技術的なハードルはゼロ
- 週末でできること: Neo4jをローカルで立ち上げて、Claude Codeのスキルとして「/ingest」を定義してみる。Dockerがあれば30分で環境は立つ
- 本格的にやるなら: BGE-M3をローカルで動かして、ChromaDBかNeo4jと繋ぐ。VRAM 8GB以上あれば実用的な精度が出る
ディレクトリ設計アプローチは、今日から始められる。グラフDB連携は、方向性を決めてから実装する話だ。CLAUDE.mdに「何をどこに入れるか」のルールを書くことから始めるのが、実際に動いている人たちの共通点だ。
ThreadPost開発との接点
個人でSaaSを開発していると、調査メモ・実装ログ・アイデアメモが確実に散らかる。「あの実装どうやったっけ」を毎回調べ直すコストは、積み重なると馬鹿にならない。
Claude Codeをエージェントとして使い、ローカルの開発ログを構造化して検索できる状態にする——この設計は、1人開発者にとって「過去の自分を検索する」仕組みになる。
「使うほど賢くなる」という表現、最初はマーケティングっぽいなと思ってた。でもグラフDBの構造を見ると、本当にそうなんだよな。エンティティが増えるたびにエッジが張られて、コミュニティが再構築される。これ、ノートツールじゃなくて「育てるDB」の話だ。ThreadPostの開発ログを全部突っ込んで、「あの機能どう実装したっけ」をグラフ検索で引けるようになったら面白そうだと思ってる。まず開発ログをちゃんと書く習慣が先だけど。
FAQ
Q1. Claude Codeを使ってエンティティ抽出やファイル操作を行うメリットは何ですか?
最大のメリットは、外部APIを一切呼び出さずに処理が完結することだ。
通常のGraphRAG構築では、ドキュメントからエンティティを抽出するためにLLM APIを呼び出す。OpenAIやAnthropicのAPIキーが必要で、処理したテキスト量に応じてトークンコストが発生する。大量のドキュメントを処理するとコストが積み上がる。
Claude Codeのスキルとして定義すると、Claude自体がローカルのファイルを読んでエンティティを抽出し、Neo4jやObsidianに書き込む。APIキー不要、トークンコストなし、外部通信なし。セキュリティポリシーが厳しい環境でも動かせる。ローカルのファイルシステムとDBを直接操作できるため、シームレスなナレッジ管理システムが構築できる。
Q2. VRAM 8GBのローカル環境でも実用的なRAGは構築可能ですか?
可能だ。 ただし、VRAMの使い方を設計段階から考える必要がある。
埋め込みモデルにBGE-M3を使うと、VRAM消費はピークで約2.5GB。100言語以上に対応し、8192トークンまで入力できる。日本語クエリで英語ドキュメントを検索するクロスリンガル検索の精度が特に高い。
LLMにはQwen2.5-32Bをllama.cppで量子化して動かす選択肢がある。32Bモデルを8GBに収めるには量子化レベルの調整が必要だが、実用的な精度は出る。
注意点は、BGE-M3とLLMを同時に動かすとVRAMが競合すること。バッチ処理のタイミングをずらすか、埋め込み処理とLLM推論を分けて実行する設計が必要だ。完全ローカル化の代償として、この制約は受け入れる必要がある。
Q3. GraphRAGと通常のベクトル検索RAGの違いは何ですか?
情報の「意味の近さ」だけで検索するか、「関係性の構造」も使って検索するかの違いだ。
通常のRAGは、テキストをベクトル化してコサイン類似度で近いチャンクを引っ張る。「マイクロサービス」で検索すれば、意味的に近い文章が返ってくる。シンプルで速い。
GraphRAGは、知識をエンティティ(人物・技術・概念など)とその関係性(「runs_on」「manages」「motivates」など)のグラフとして構造化する。「マイクロサービス」で検索すると、ベクトル的に近いチャンクに加えて、グラフ上で繋がっている「Kubernetes」「Docker」「Team Independence」といったエンティティも一緒に取得できる。
「AとBの共通点は?」「この技術を選んだ理由は?」といった、複数ドキュメントをまたぐ多段推論が可能になる。単一ドキュメントの要約なら通常RAGで十分。複数の知識を横断して推論したいならGraphRAGが強い。
まとめ
Claude Codeは「コードを書くツール」を超えた。ローカルのファイルを読んで、エンティティを抽出して、グラフDBに書き込む——その一連の動きが、外部API不要で動く。
APIコストとセキュリティ制約が、ローカルAI環境の構築を加速させている。
知識の関係性を動的に構築するグラフDBアプローチと、ディレクトリとCLAUDE.mdでルールベースに整理するアプローチ——どちらも「情報の構造設計」が先に来る。AIに任せる前に、人間がルールを書く。
使うほど賢くなる環境を育てている人と、毎回ゼロから検索している人の差は、時間が経つほど開いていく。
Claude Codeを使った開発ノウハウや、ローカルAI環境の知見——こういった情報をSNSで発信・共有するなら、ThreadPostが使いやすい。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
