
LLMを使ったプロダクト開発で、誰もが一度はぶつかる壁がある。それは、AIに会話や思考の進行を任せると、高確率で迷子になるという問題だ。
結論から言うと、LLMにすべてを委ねるのは非常に危険だ。AIエージェントに安定した思考プロセスを持たせるには、進行管理や検証といった外枠をシステム側で強固に設計する必要がある。
本記事では、1人SaaS開発者の僕が実践する、AIエージェントの思考を制御する設計パターンを12個紹介する。初心者でも今日から取り入れられるように、具体的な手法をカテゴリ別にまとめた。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
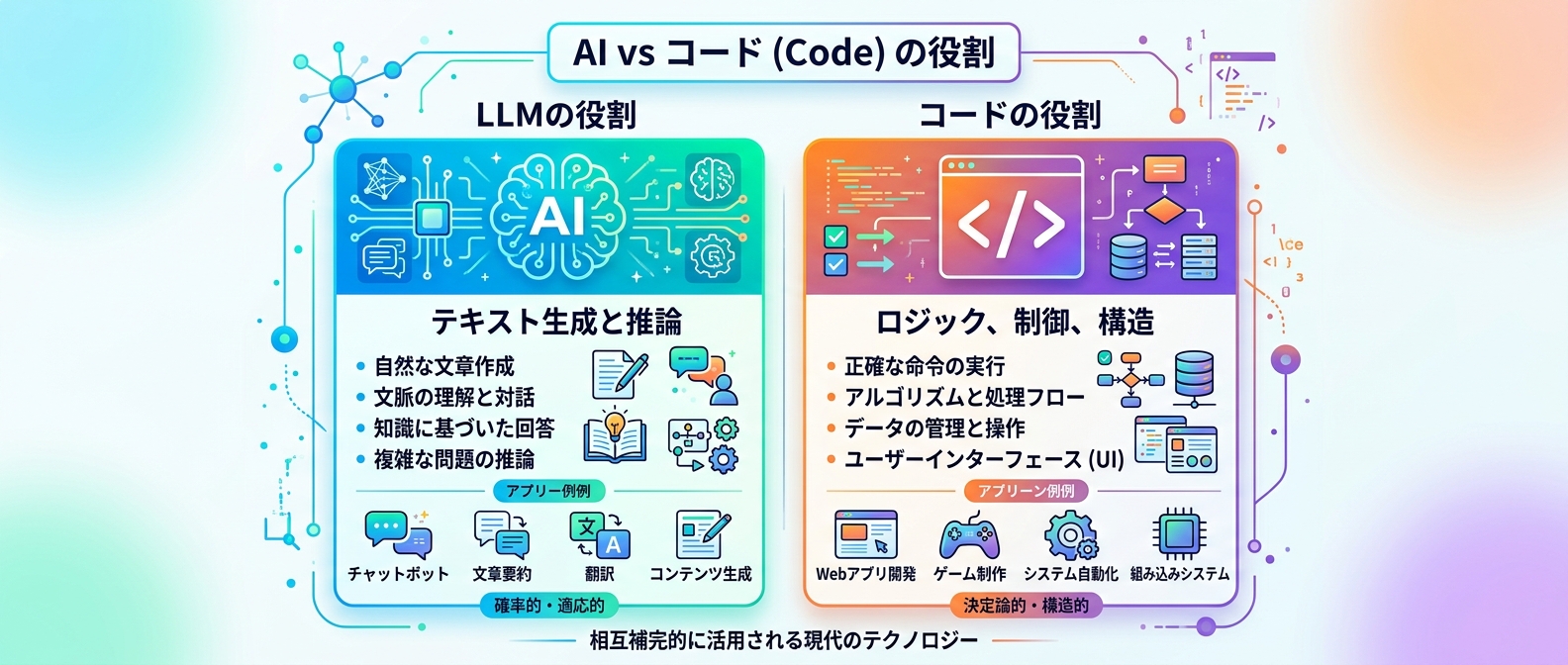
LLMに任せる領域とコードで制御する領域の比較
手法の解説に入る前に、まずはAIエージェント設計の基本原則を整理しよう。
| 制御対象 | 担当 | 理由・特徴 |
| --- | --- | --- |
| テキスト生成 | LLM | 自然な会話やアイデア出しに特化させる |
| ユーザーの意図推論 | LLM | 自然言語の揺らぎを吸収して柔軟に分類する |
| 会話のフロー制御 | コード | 次のアクションをシステム側で確実に決める |
| 状態管理・スコア計算 | コード | 単調増加などの制約を設け、UIの破綻を防ぐ |
| エラー時の修復 | コード | 失敗理由を分析し、確実なリトライ手順を回す |
この役割分担を意識するだけで、AIの暴走は劇的に減るはずだ。
対話・フロー制御編
1. 既存の対話フレームワークの導入
LLMに自由な会話をさせると、同じ質問を繰り返したり、核心に触れない浅い提案で終わったりする。これを防ぐには、ゼロからプロンプトをこねくり回すのではなく、人間が長年使ってきた会話の構造を導入するのが一番だ。
たとえば、コーチングの世界で有名な「GROWモデル」や、医療現場の「SOAPノート」などの型をそのままワークフローに組み込むといい。目標、現状、選択肢、意志という4つのフェーズの情報をコンプリートすれば、自ずとゴールに辿り着ける。このように明確な目標を設定することで、AIの会話品質は驚くほど安定する。魔法のプロンプトを探すより、プロの思考フローをトレースさせるのが近道だ。
2. 進行管理のコード制御
次に何を聞くかの判断をLLMに任せると、会話の無限ループが発生しがちだ。たとえば、目標について十分に聞き出せているのに、また目標を深掘りしようとするなど、LLMは次にどこへ行くかの判断が絶望的に苦手だと言える。
解決策はシンプルだ。LLMにはテキスト生成のみを担当させ、会話の状態遷移やフロー制御はすべてシステム側のプログラムコードで制御する。評価とテキスト生成だけをLLMに任せ、次のアクションはコードで決める。これだけで会話のループは完全に消滅し、ユーザーを確実にゴールまで導けるようになる。
しんたろー:
Claude Codeを使って1人SaaSを開発していると、LLMに複雑なロジックを任せすぎてデバッグ地獄に陥ることがよくある。
LLMにはテキスト生成だけを任せ、フロー制御はTypeScriptでガチガチに固めるのが一番開発スピードが上がるし、精神衛生上も良い。
3. 状態スコアの単調増加制約
会話の進捗度合いをLLMに都度評価させると、UIが破綻する原因になる。たとえば、前回は目標の明確さが80点だったのに、次のターンで再評価させたら突然30点に下がるといった事態が起こる。これでは画面上の進捗バーが行ったり来たりして、ユーザーを混乱させてしまう。
ここでの対策は、スコアは前の値より下がらないといったハードコードの制約をシステム側に入れることだ。状態管理をLLMに委ねず、コードで単調増加を保証する。AIの評価を無条件に信じないことが、安定したプロダクト作りの鉄則だ。
4. 自然言語ベースの推論アーキテクチャへの移行
固定の質問IDを使った条件分岐処理は、LLMが動的に質問を作るようになると完全に破綻する。たとえば、質問1、質問2と進む前提でコードを書いていると、AIが文脈に合わせて独自の質問を生成した瞬間、裏側の分析ロジックがIDを見つけられずエラーを吐き続けることになる。
これを防ぐには、ユーザーの回答から現在の課題ドメインを推論・分類するタスクもLLMに任せるといい。自然言語ベースで処理を繋ぐアーキテクチャに切り替え、固定IDへの依存を捨てることで、柔軟かつエラーに強い対話システムが構築できる。
5. コンテキストエンジニアリングによる人格形成
AIに特定の判断基準を持たせるために、膨大なデータとGPUリソースを使ってファインチューニングを行う必要はない。プロンプトに含めるコンテキストを工夫するだけで、特定の考え方の癖や興味の方向性を持たせた人格を形成できる。
モデルの内部構造は一切変えず、読ませる外部情報を変えるアプローチだ。たとえば、過去20年分の日記や特定の価値観をまとめたテキストを読み込ませるだけで、AIの出力は劇的に変わる。手術ではなく教育によってAIを育てるこの手法は、個人開発者にとって非常に強力な武器になる。
人格・記憶の形成編
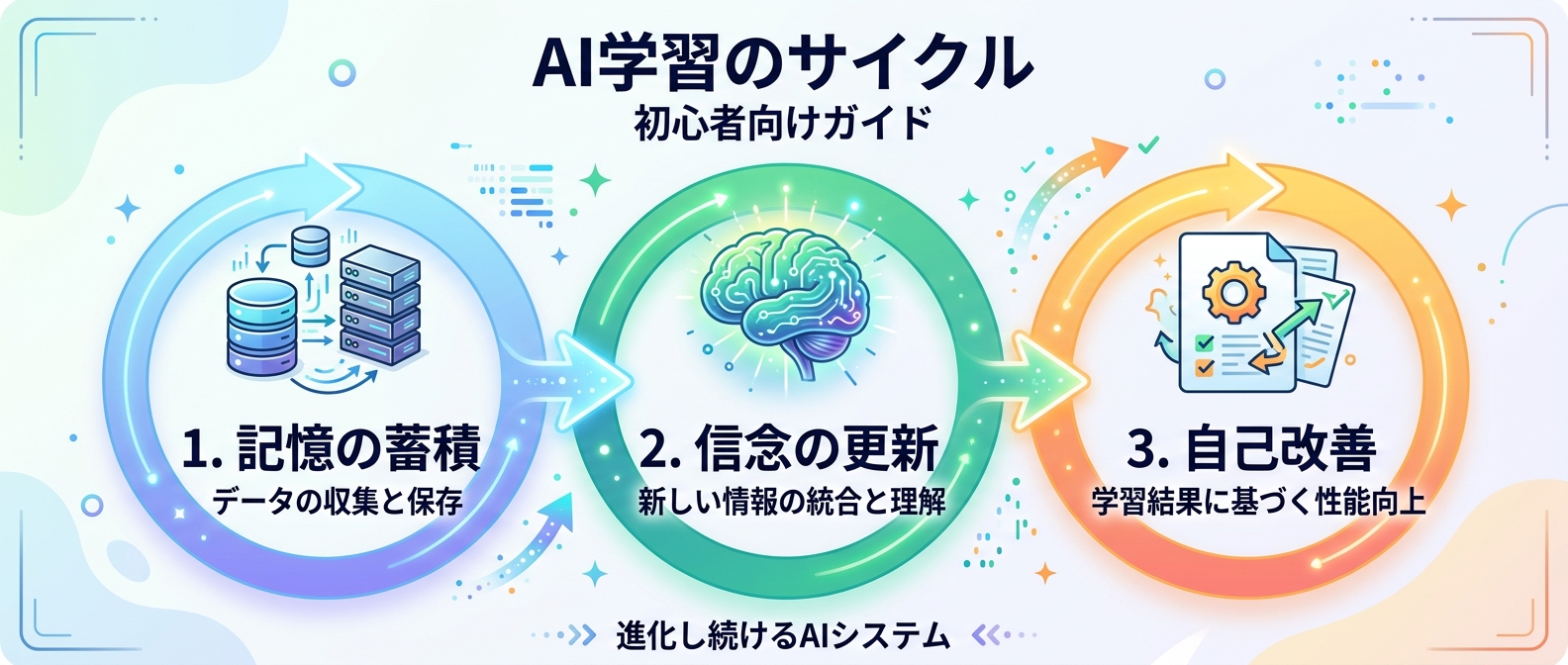
6. 記憶の蓄積とオンデマンド引き出し
AIに長期的な文脈を維持させるには、過去の全ログに対してインデックスを貼り、必要な記憶をオンデマンドで引き出せる仕組みが必要だ。すべての過去ログを毎回プロンプトに詰め込むと、あっという間にトークン制限に引っかかってしまう。
そこで、全文検索できるデータベースを構築し、AIが必要なときに特定の記憶を呼び出せるようにする。たとえば、ユーザーの過去の悩みを検索して回答に組み込むといった処理だ。これにより、過去の会話を踏まえた上で、一貫性のある思考や対話が可能になる。
7. 信念の外部ファイル化と動的書き換え
AIの行動原理や価値観を「信念」として外部ファイルに持たせる手法もおすすめだ。AIが外部から新しい情報を取り込むたびに、この信念ファイルを少しずつ書き換える仕組みを作る。
たとえば、新しい技術記事や論文を読み込んだ際、AI自身の判断基準がどう変わったかをテキストファイルに追記・更新していく。これにより、AI自身に判断基準をアップデートさせる自己改善を促すことができる。固定されたプロンプトではなく、経験とともに成長するプロンプトを作るイメージだ。
8. 自己改善のフィードバックループ構築
記憶の蓄積と信念の書き換えを連動させ、出力の質を向上させるループを回す。1回のサイクルで得られた改善が次回の改善量を増やす状態を作れれば、AIの能力は自律的に向上していく。
外部入力から記憶を蓄積し、信念を書き換え、出力の質が変わり、それがまた新しい外部入力を呼ぶ。たとえば、AIが自分で生成したコードを評価し、その反省を信念ファイルに書き込んで次のコーディングに活かすといった具合だ。このサイクルが回ると、AIは際限なく賢くなるポテンシャルを秘めている。
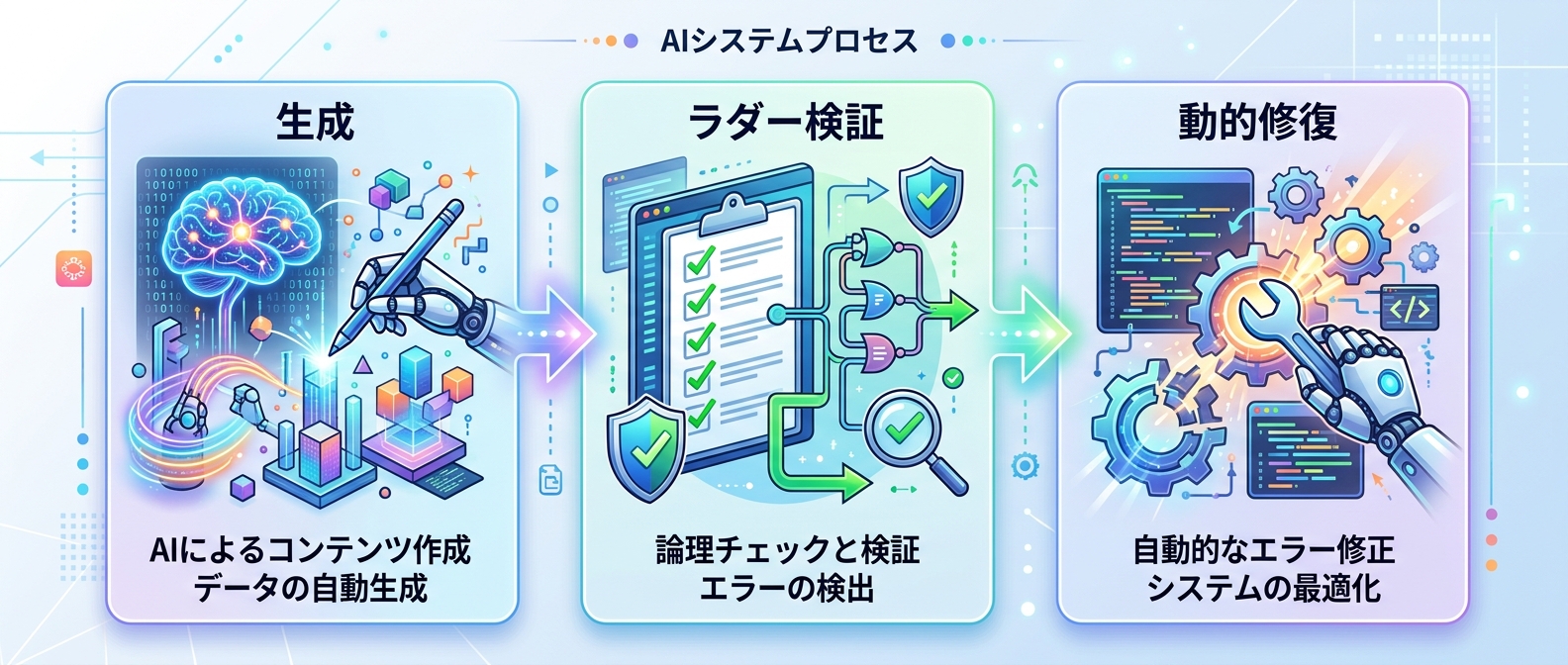
9. 代謝モデルによる出力管理
生物の代謝をモデルにし、生成、検証、修復、巻き戻しという一連の流れをコードレベルで保証する実行パターンだ。AIの出力を無条件に信用してそのままユーザーに見せるのは非常に危険だ。
システム側で厳密に品質を管理し、問題があれば修復し、どうしてもダメなら排出する。たとえば、生成されたテキストにNGワードが含まれていないか検証し、含まれていれば再生成させ、3回失敗したらエラーメッセージを返す。この代謝の仕組みを取り入れることで、システム全体の堅牢性が跳ね上がる。
10. 実行単位の定義と依存関係の整理
LLMのタスクを実行単位に分解し、並列実行可能なものや前の出力に依存するものなど、タイプを明確に定義する。複雑なエージェントの処理も、この小さな単位に分割することで整理しやすくなる。
たとえば、複数エージェントの独立した調査タスクは並列で走らせて高速化し、その調査結果をまとめるタスクは順次実行するといった制御だ。タスクごとの依存関係を整理することで、効率的かつ安全にAIを動かすことができる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
実行・品質管理編
11. 4段階のラダー検証
出力結果を4段階の梯子で検証する仕組みだ。第1段階は出力の存在確認、第2段階は文字数などの最低限の品質、第3段階は指示との整合性、第4段階は全体比較での差別化となる。
レベルが上がるほど意味的な検証になり、第1段階で失敗した場合は即座に処理を停止させる。たとえば、出力が空っぽなら即エラーにし、文字数が足りていれば次のステップで内容の正確性をチェックする。段階的なチェックを設けることで、無駄なAPIコールを減らしつつ品質を担保できる。
12. 失敗理由をヒントにした動的修復
検証で失敗した場合にすぐ諦めるのではなく、なぜ失敗したかをヒントとして抽出し、プロンプトに動的に追加して再実行させる。単なるリトライではなく、失敗から学ばせるアプローチだ。
たとえば、文章が短すぎるといった具体的な理由をAIに伝え、「もっと詳しく書いて」と指示を足して再実行する。これにより、AI自身に問題を認識させ、自律的なエラーからの回復が可能になる。システム側で手厚くサポートすることで、最終的なアウトプットの質は劇的に向上する。
しんたろーのイチ推しTips
12個紹介した中で、僕が一番重要だと感じるのは「代謝モデルによる出力管理」だ。
ThreadPostの開発でもAIの出力をそのまま信用せず、検証と修復のサイクルを回すようにしてから、エラー率が劇的に下がった。
よくある質問(FAQ)
Q1: AIの会話がループしたり迷子になったりするのを防ぐには?
LLMに会話の進行まで任せてしまうのが主な原因だ。解決策として、LLMにはユーザーの回答の評価とテキストの生成のみを任せるのが効果的だ。会話の状態遷移やフロー制御はシステム側のプログラムコードで厳密に管理するように設計しよう。また、既存の対話フレームワークを導入することで、会話のゴールが明確になり、AIが迷子になるのを防ぐことができる。
Q2: ファインチューニングなしでAIに特定の人格を持たせることは可能?
可能だ。コンテキストエンジニアリングと呼ばれる手法を活用し、プロンプトとして読み込ませる外部情報を工夫するだけで実現できる。過去の対話ログや価値観をまとめた外部ファイルをAIに読み込ませることで、特定の考え方の癖を持たせた人格をシミュレートできる。外部の知識を取り込むたびにこのファイルを動的に更新する仕組みを作れば、AIを継続的に成長させることも可能だ。
Q3: AIの出力品質を安定させるための検証はどのように実装すべき?
出力を段階的にチェックするラダー検証の仕組みをコードレベルで実装するのが有効だ。第1段階で出力が空でないかを確認し、第2段階で文字数不足やエラーの混入がないかを見る。第3段階でプロンプトの指示要件を満たしているかを確認し、第4段階で他の出力と差別化できているかを比較する。機械的なチェックから高度な意味的チェックへと段階を踏むことで、品質を確実に担保できる。
Q4: AIがエラーを出した際、自動で修正させる仕組みは作れる?
検証プロセスと修復のロジックを組み合わせることで実装可能だ。AIの出力が検証で不合格となった場合、単にエラーとして処理するのではなく、なぜ失敗したのかという具体的な理由を抽出する。そのヒントを元のプロンプトに追記した上でAIに再実行させることで、AI自身に問題を認識させて自律的に修正を促すことができる。
Q5: ユーザーの回答に応じて動的に質問を変えるにはどう設計すればいい?
従来の固定IDによる条件分岐処理では、AIが動的に生成する質問に対応しきれずエラーになりがちだ。そのため、固定IDへの依存を捨て、ユーザーの回答内容から現在の課題ドメインを推論するタスク自体もLLMに任せるのがおすすめだ。自然言語ベースの推論アーキテクチャを採用しつつ、最終的な状態遷移やエラー時のフォールバック処理はシステム側で安全網を張っておくことが重要になる。
まとめ
今回は、AIエージェントの思考や人格を制御する12の設計パターンを解説した。
結論として、LLMにすべてを丸投げするのではなく、人間がシステム側でしっかり手綱を握ることが成功の鍵だ。まずはフロー制御をコードに切り出すところから始めてみるといい。
AIエージェントの制御で一番苦労したLLMの暴走エピソードがあれば、ぜひ教えてほしい。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
