
LLMのAPI料金が想定以上に膨らんで驚いた経験を持つ人は多いはずだ。
個人開発でAIエージェントやアプリを作っていると、APIの従量課金コストは非常に重要な問題だ。
開発に夢中になってAPIを叩き続けていたら、月末にとんでもない請求が来たという話はよく聞くものだ。
結論から言うと、プロンプトキャッシュやバッチ処理などの技術的アプローチを使えば、APIコストは最大95%削減できる。
今回は、1人開発者として毎日AIと向き合う僕が、LLMのAPIコストを劇的に下げる9つのアプローチの解説だ。
初心者でもすぐに実践できる具体的な設定方法を中心にまとめたものだ。
この記事を読めば、コストを気にせずにAI開発に集中できる環境が手に入るはずだ。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
コスト削減の基本とトークン管理
1. トークン消費の仕組みと推論コストを把握する
LLMのAPI料金は、入力トークンと出力トークンの合計で計算される仕組みだ。
最近の思考するモデルでは、ユーザーに見えない推論トークンも出力と同じ単価で課金される仕様になっている。
最終的な回答が短くても、内部で長大な推論が行われると想定以上のコストがかかるのだ。
たとえば、画面上の回答が50トークンでも、裏で500トークンの推論があれば10倍のコストになる。
まずはこの課金構造を理解することが、コスト最適化の第一歩だ。
具体的には以下の点に注意すべきだ。
- 思考プロセスを必要とする複雑なタスクは推論コストが高くなる
- 単純なタスクには軽量なモデルを選ぶか、思考の強度を低く設定する
- 思考トークンは出力トークンと同じ単価で課金されることを意識する
これらを意識するだけで、無駄なコストの発生を未然に防ぐことができる。
2. 長大コンテキスト入力時の料金割増に警戒する
主要モデルの多くが100万トークン以上のコンテキストウィンドウを持つようになった。
しかし、一定のトークン数を超えると入力単価が跳ね上がるモデルが存在するものだ。
たとえば特定のモデルでは、20万トークンを超えた段階で料金が数倍に上がる仕様になっている。
長大なPDFや巨大なコードベースをそのまま渡すのは非常に危険だ。
大量のデータを入力する際は、事前に料金体系の境界線を確認しておく必要がある。
対策としては以下の方法が有効だ。
- 段階課金の有無を事前に確認する
- 20万トークンなどの境界線を超えるか設計段階で把握する
- 巨大なコードベースを渡す際は、関連するファイルだけに絞り込む
便利だからといって何でもかんでも投げ込むと、月末の請求書を見て後悔することになる。
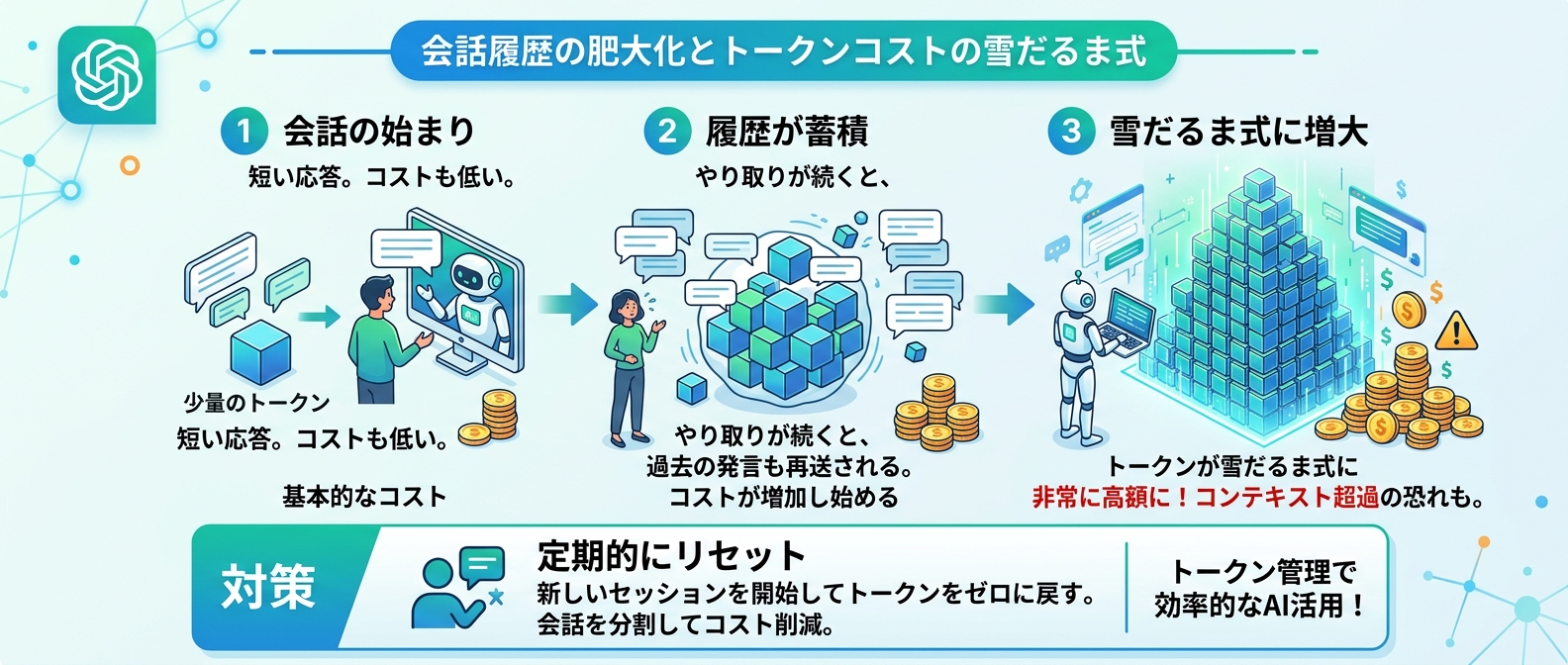
3. ステートレスAPIの会話履歴による累積コストを防ぐ
LLMのAPIは過去の記憶を持たないステートレスな設計になっている。
会話を続けるには、毎回これまでのやり取り全体をAPIに送り直す必要がある。
これが積み重なると、入力トークン数が雪だるま式に増加していくのだ。
1ターン完結と100ターン継続では、累積入力トークンに約1675倍もの差が出ることがある。
長時間のセッションはコスト肥大化の最大の原因になるため、不要な履歴は定期的にリセットすべきだ。
具体的に実践すべきルールは以下の通りだ。
- 1つのタスクが完了したら、必ず新しいセッションを立ち上げる
- 過去のやり取りで重要な決定事項だけを要約して別の場所にメモしておく
- システムプロンプト自体をなるべく簡潔に保つ
これらを徹底するだけで、無意識に膨れ上がる累積コストを大幅にカットできる。
システム側の最適化テクニック
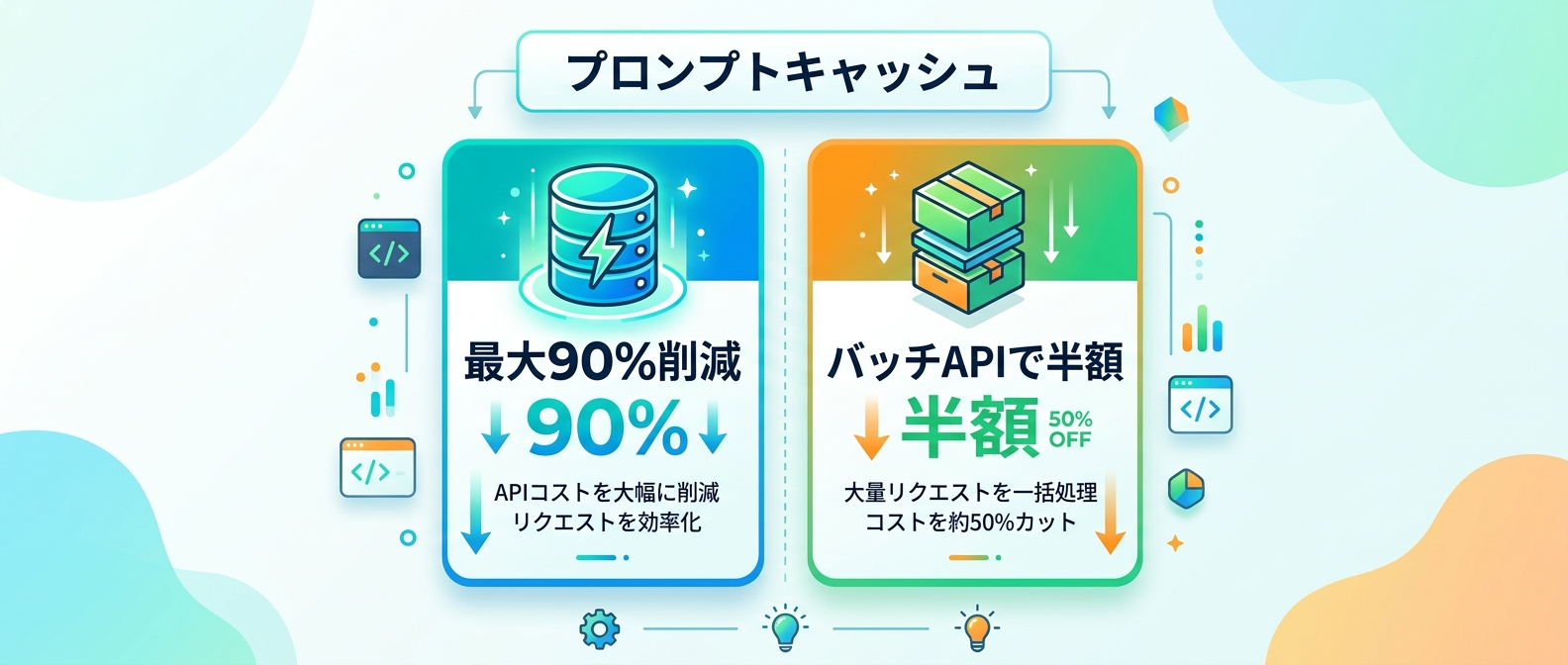
4. プロンプトキャッシュで入力コストを最大90%削減する
同じシステムプロンプトや参照文書を繰り返し送信する場合、プロンプトキャッシュが圧倒的に効果的だ。
サーバー側にデータをキャッシュさせることで、2回目以降の読み込みコストを基本料金の10%に抑えることができる。
これにより、最大90%のコスト削減が可能になる。
特にエージェントワークフローのように、毎回同じルールや背景情報を読み込ませる処理で威力を発揮するのだ。
即座に効果が出るため、一番最初に設定すべき項目だ。
キャッシュを活用すべき具体的なシーンは以下の通りだ。
- 数千文字に及ぶ詳細なシステムプロンプトを使う場合
- 製品マニュアルや社内規定などの固定ドキュメントを参照させる場合
- 複雑なフォーマット指定や出力例を多数含める場合
この設定をオンにするだけで、APIの利用明細の数字が劇的に変わるはずだ。
5. バッチAPIを活用してコストを半減させる
データ分析や大量のテキスト分類など、リアルタイムな応答が不要な処理にはバッチAPIが最適だ。
最大1万件のリクエストをまとめて送信し、24時間以内に結果を取得する非同期処理になる。
この方法を使うだけで、通常料金の50%割引で処理できる。
急ぎではない過去データの処理や定期的なコンテンツ生成タスクは、すべてバッチAPIに移行すべきだ。
これだけで毎月のバッチ処理コストが半分になるはずだ。
バッチAPIが活躍する代表的なユースケースは以下の通りだ。
- 大量の顧客レビューの感情分析
- 過去データのバッチ処理
- 定期的なコンテンツ生成
即時性を求められないタスクを洗い出し、計画的にバッチ処理へ回すのが賢い運用だ。
6. コンテキストの自動圧縮機能を利用する
会話が長くなりコンテキストウィンドウの上限に近づくと、モデルの応答品質が低下しやすいものだ。
これを防ぐのが、古い会話を自動的に要約して圧縮する自動圧縮機能だ。
この機能を使えば、トークン消費量を大幅に減らしつつ、重要な文脈を維持できる。
コンテキストの腐敗を防ぎ、AIが過去の指示を忘れる現象も回避できる。
長時間のチャットボット運用では必須のテクニックと言える。
自動圧縮を導入するメリットは以下の通りだ。
- 過去のやり取りの要点だけを残すため、入力コストが安定する
- ノイズとなる不要な会話が削られ、AIの回答精度が向上するのだ
- ユーザー側で手動でセッションをリセットする手間が省ける仕組みだ
ユーザー体験を損なわずにコストを抑えるための強力な武器になる。
しんたろー:
Claude Codeで毎日コードを書いている身からすると、コンテキストの肥大化は本当に厄介な問題だ。
開発セッションが長引くと、プロジェクトの背景情報を書いたファイルの読み込みだけでトークンを大量消費してしまうのだ。
だからこそ、定期的に会話をリセットして、必要な文脈だけを新しいセッションに引き継ぐ運用が欠かせないのだ。
RAGとプロンプトの工夫
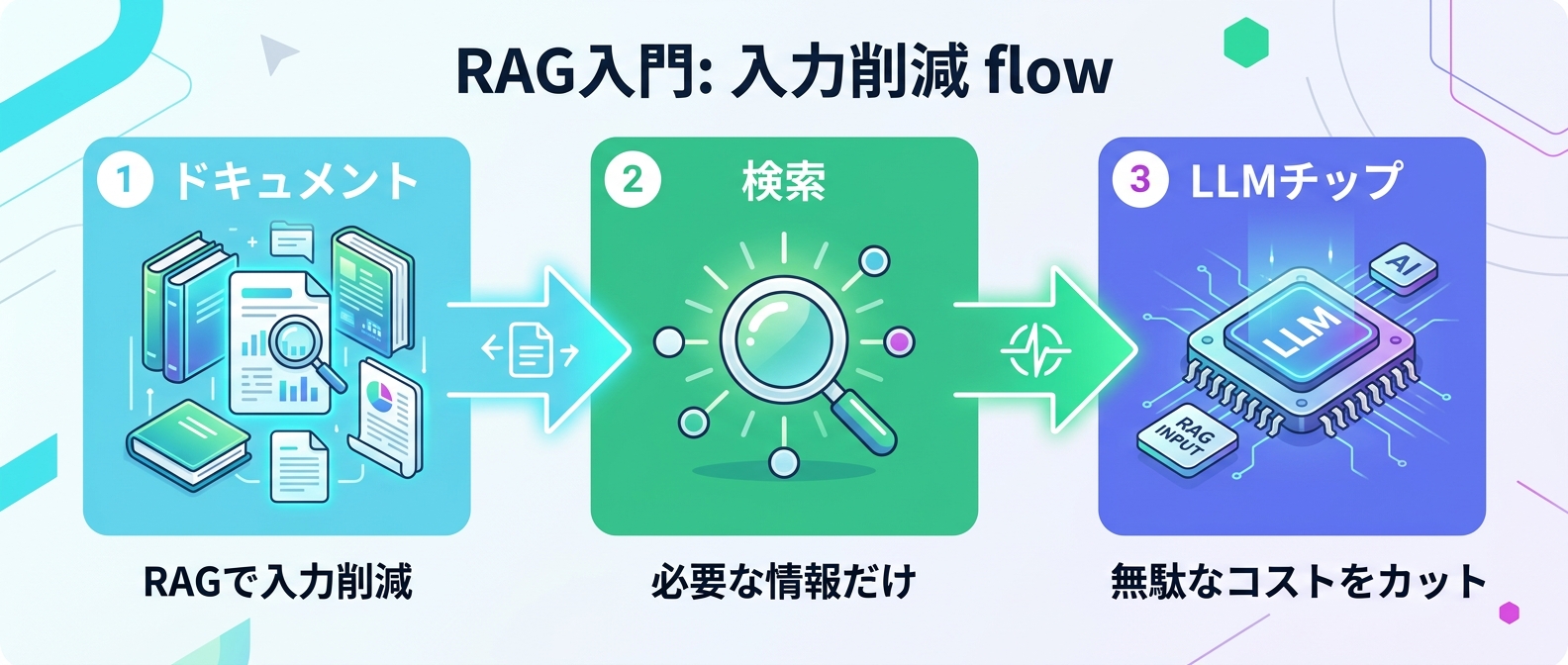
7. RAG導入で入力トークンを最小化する
LLMにすべての知識をプロンプトとして渡すのは非常に非効率だ。
ここで役立つのが、必要な情報のみを検索して抽出するRAG(検索拡張生成)の導入だ。
ユーザーの質問に関連する部分だけをデータベースから探し出し、それだけをLLMに渡す仕組みになる。
巨大なマニュアルを毎回すべて入力する必要がなくなるため、入力トークン数を劇的に削減できる。
コストを抑えつつ、ハルシネーションを防ぐ効果も高いのだ。
RAGを構築する際のポイントは以下の通りだ。
- ベクトル検索だけでなく、キーワード検索も組み合わせる
- 検索結果の関連度をスコアリングして上位のテキストだけを採用する
- 参照元の情報がない場合は回答しないルールを徹底する
初期構築の手間はかかるが、長期的なコスト削減効果は計り知れないのだ。
8. チャンキング最適化でノイズと無駄なコストを削る
RAGシステムにおいて、ドキュメントを分割するチャンキングの設計はコストに直結するものだ。
チャンクが大きすぎると不要なノイズが増えて入力トークンを無駄に消費してしまうのだ。
逆に短すぎると文脈が切れてしまい、正しい回答が生成できないのだ。
適切なサイズで分割し、意味のあるメタデータを付与することが重要だ。
これにより、効率的な検索と無駄のない生成が両立できる。
チャンキング最適化の具体的なコツは以下の通りだ。
- 見出しや段落の区切りなど、意味のまとまりごとに分割する
- ドキュメントの作成日や部署名などのメタデータを付与して検索精度を上げる
- 複数のチャンクサイズを試して、自分のデータに最適な長さを探るべきだ
検索の精度が上がれば、LLMに渡すテキスト量も最小限に抑えることができる。
9. プロンプト設計で無駄な出力トークンを抑制する
LLMの暴走や不要な長文回答を防ぐには、プロンプト設計での明確な指示が必要だ。
提供された情報のみを使って回答することや、不明な場合は情報が見つからないと答えることをルール化すべきだ。
これにより、AIが推測で長々と語り出すのを防ぐことができる。
出力トークンの消費を抑えることは、直接的なコスト削減につながるのだ。
シンプルなプロンプト設計こそが、持続可能な運用の鍵になる。
無駄な出力を防ぐためのプロンプトの工夫は以下の通りだ。
- 提供されたコンテキストのみを使って回答するよう指定する
- 不明な場合は「情報が見つかりません」と答えるよう指示すべきだ
- 推測で補完しないようルール化する
これらの制約を設けることで、APIのレスポンス速度も上がり、一石二鳥の効果が得られる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
しんたろーのイチ推しTips
個人的には、バッチAPIの割引率の高さもかなり魅力的だ。
リアルタイム性が求められないログ分析やデータ整理のタスクなら、これを使わない手はないのだ。
RAGの構築は少し手間がかかるが、長期的な運用コストを考えると絶対に導入しておきたい技術だと言える。
コスト削減アプローチの比較と効果
どのアプローチから手をつけるべきか迷う人のために、効果と導入難易度を一覧にしたものだ。
自分のプロジェクトに合ったものから試してみるべきだ。
| アプローチ | 期待できる削減効果 | 導入難易度 | 最適な用途 |
| :--- | :--- | :--- | :--- |
| プロンプトキャッシュ | 最大90%(入力) | 低 | エージェント開発、定型プロンプトの反復 |
| バッチAPI | 50%(全体) | 中 | データ分析、バッチ処理、コンテンツ生成 |
| RAG導入 | 大幅な入力削減 | 高 | 社内文書検索、カスタマーサポート |
| 自動圧縮機能 | 中〜大(累積入力)| 中 | 長時間のチャットボット運用 |
| プロンプト最適化 | 小〜中(出力) | 低 | 全てのLLMアプリケーション |
結論から言うと、まずは導入難易度が低くて効果が高いプロンプトキャッシュから始めるのがおすすめだ。
これだけで目に見えてAPI料金が下がるはずだ。
よくある質問
Q1: プロンプトキャッシュはどのように設定すればいいか
APIリクエスト時のパラメータにキャッシュ制御の指定を追加するだけで設定できる。
特定のテキストブロックにキャッシュを有効化する設定を付与すると、サーバー側に数分間データが保持される仕組みだ。
これにより、同じプロンプトを繰り返し送信する際の2回目以降の読み込みコストが通常の10%に抑えられる。
エージェント開発などでは必須の設定と言える。
Q2: バッチAPIはどのようなタスクに向いているか
リアルタイムな応答が不要な非同期処理に最適だ。
大量の顧客レビューの感情分析や、過去データのバッチ処理、定期的なコンテンツ生成などが該当するものだ。
最大1万件のリクエストをまとめて送信し、最大24時間以内に結果を受け取る仕組みになっている。
通常料金の50%割引で利用できるため、急ぎではない大量処理のコストを半減できる。
Q3: チャットボットを長く使っていると料金が高くなるのはなぜか
LLMのAPIは過去の記憶を持たないステートレスな設計になっている。
そのため、会話を成立させるには毎回これまでのやり取り全体をAPIに送り直す必要がある。
会話のターン数が増えるほど入力トークン数が雪だるま式に増加し、累積コストが跳ね上がるのだ。
これを防ぐには、古い会話を要約して圧縮する機能の活用が効果的だ。
Q4: 推論トークンとは何か、料金はかかるのか
推論トークンとは、最新の思考するモデルが回答を生成する前に、内部で論理的な計算を行うために消費するトークンのことだ。
ユーザーの画面には表示されないが、この推論トークンも出力トークンと同じ単価でしっかり課金される仕組みだ。
そのため、画面上の回答が短くても、裏で複雑な推論が行われている場合は想定以上のコストが発生するのだ。
複雑なタスクを依頼する際は注意が必要だ。
Q5: RAGを導入するとコスト削減につながるのは本当か
本当だ。
ユーザーの質問に関連する情報だけをデータベースから検索し、必要な部分だけをLLMに渡して回答を生成させることができる。
巨大なマニュアルや規定集を毎回すべてプロンプトに入力する必要がなくなるため、入力トークン数を劇的に削減できる。
結果としてAPIの利用コストを大幅に抑えることが可能になる。
まとめ
LLMのAPIコストは、仕組みを理解して適切なアプローチをとるだけで劇的に下げることができる。
特にプロンプトキャッシュとバッチAPIの活用は、今日からすぐに始められる強力なテクニックだ。
トークンの消費ルールを把握し、無駄な入出力を削ることで、持続可能なAI開発が実現できる。
まずは自分のプロジェクトのトークン消費量を確認するところから始めるべきだ。
コスト最適化は一度設定してしまえば、その後ずっと効果が持続するものだ。
浮いたコストでより高性能なモデルを試すこともできるようになる。
この記事で紹介したアプローチを一つずつ実践して、効率的な開発環境を構築すべきだ。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
