
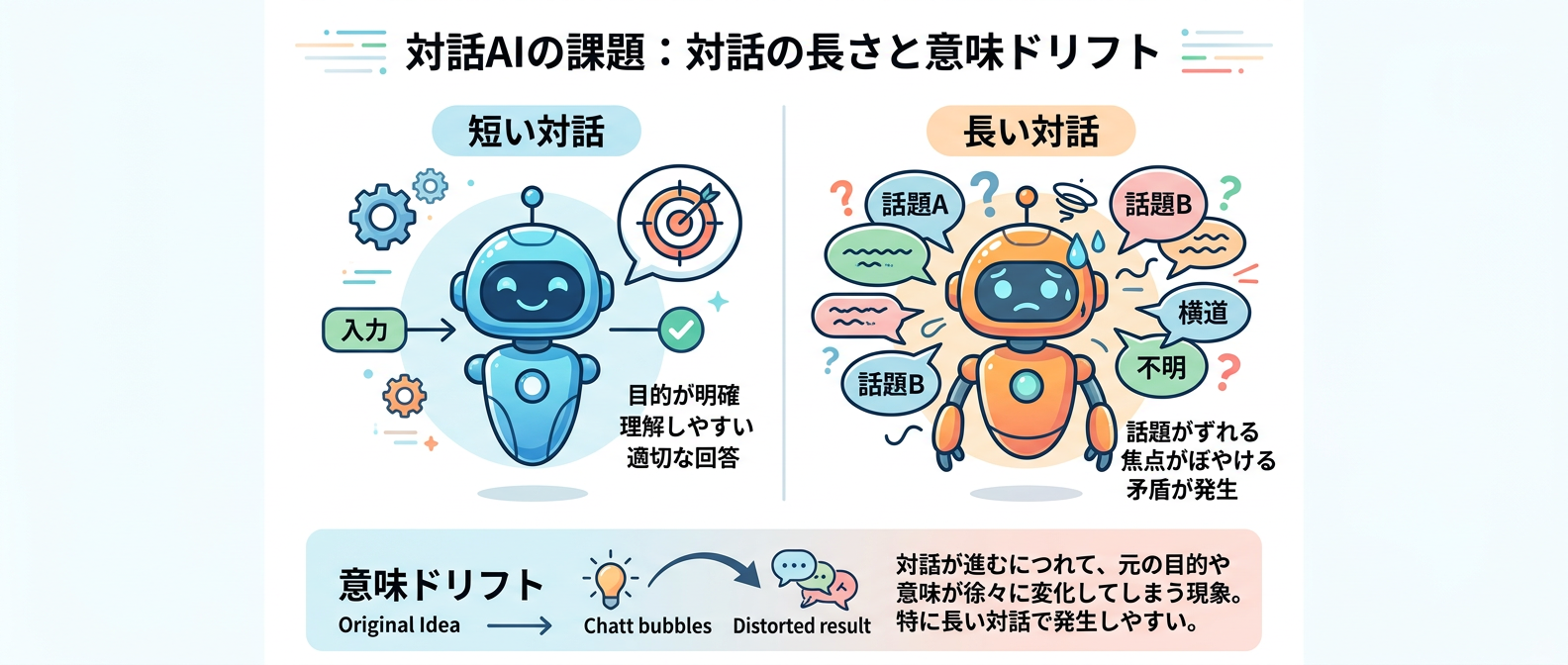
AIと長く会話していると、急に設定を忘れたり、話が噛み合わなくなったりした経験はないだろうか。
最初は賢く答えていたのに、やり取りを重ねるうちにどんどん的外れな回答になっていく。
多くの人が経験するこの現象は、AIの不具合でもプロンプトのせいでもない。
これは意味ドリフトと呼ばれる、現在のAIが抱える数学的な宿命だ。
今回は、この意味ドリフトを防ぎ、AIの精度を最後まで保つための具体的な6つのステップを解説する。
結論から言うと、長いチャットを捨てて「共有黒板」を使うのが一番の近道だ。
この記事を読めば、AIが途中でボケてしまう原因と、その確実な対処法がわかるはずだ。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
前提知識
対策を始める前に、特別なツールや追加の費用は一切必要ない。
普段使っているAIチャット画面と、メモ帳代わりのテキストファイルがあれば十分だ。
プログラミングの深い知識がなくても、AIとの接し方や運用ルールを変えるだけで今日からすぐに実践できる。
まずは「1つの長いチャットで全てを解決しようとする」という習慣を捨てる準備をしておこう。
それだけで、AIからの回答精度は見違えるほど安定するようになる。
安心してほしい、手順はとてもシンプルだ。
ステップ1:意味ドリフトの正体を知る
AIとの対話が長くなると、論理が破綻して設定を忘れてしまう現象が意味ドリフトだ。
多くの人は、これを「自分のプロンプトの書き方が悪いからだ」と考え、何度も指示を書き直す。
しかし、プロンプトの工夫だけでこの問題を完全に解決することは不可能だ。
なぜなら、意味ドリフトはAIの不具合や癖ではなく、現在の生成AIの根幹にある数学的な限界だからだ。
現在のAIは、膨大なデータから「次の一文字」の確率を計算し、サイコロを振るように言葉を選んでいる。
どんなに正解の確率が高くても、わずかなハズレを引く可能性が数学的に残されている。
その微細な間違いが次の入力として固定され、雪だるま式にエラーが蓄積していく仕組みだ。
たとえば、たった1%のノイズでも、会話が長く続けば最終的に論理が完全に脱線してしまう。
これはAIが言葉を紡ぐ仕組みそのものに起因する問題だ。
だからこそ、気合いやプロンプトの微調整で乗り切ろうとするのはやめるべきだ。
まずは、AIが本質的に抱える限界を正しく知ることが、対策の第一歩となる。
ステップ2:長文コンテキストの罠を理解する
AIに長い文章や過去のやり取りを大量に読み込ませると、重要な初期設定を忘れてしまう現象が起きる。
これは、直近の会話履歴にAIの注意力が偏ってしまうことが原因だ。
専門用語でSoftmax Crowdingと呼ばれる現象だ。
AIにとって、システムプロンプトで指定した「絶対に守るべきルール」も、その後の「ただの雑談」も、区別はない。
どちらも次の一文字を予測するための等価なデータとして、同じ空間で処理される。
会話が長くなればなるほど、最初の重要な設定は新しい雑談のノイズに押し潰されてしまう。
たとえば、AIに「関西弁で話して」と設定しても、10回、20回とやり取りを重ねるうちに、突然標準語に戻ってしまうのはこのためだ。
モデルは位置的にも意味的にも近い「直近の履歴」に強い注意を向けるように作られている。
長文のコンテキストは、一見便利に見えて、実は設定の忘却を招く危険な罠だと認識しておこう。
長い文脈を保持させようとするほど、AIの頭の中は散らかっていくというわけだ。
ステップ3:プロンプトやFTへの過信を捨てる
「プロンプトを厳密に書けば防げる」「ファインチューニングで専門知識を学習させれば解決する」と考える人は多い。
しかし、これも根本的な解決にはならない。
ファインチューニングは特定の正解確率を上げる効果はあるが、不正解を選ぶ確率をゼロにはできない。
どんなに専門知識を学習させても、確率論的なノイズの混入は避けられない。
正解確率が99.9%になったとしても、残り0.1%のハズレを引いた瞬間、その微細な間違いが次の推論の前提になってしまう。
プロンプトで「絶対に忘れないで」「必ず守って」と強く書いても、物理的に設定が埋もれてしまう現実は変わらない。
プロンプトや学習による対策は、ドリフトの進行を遅らせるだけの延命措置にすぎない。
根本的な解決には、モデルの性能に頼るのではなく、システム全体の設計を見直す必要がある。
AIの出力が常に完璧であるという幻想を捨て、間違えることを前提とした仕組み作りが求められる。
ステップ4:コンテキストと生成ステップを短く保つ
意味ドリフトを防ぐ第一歩は、1回の入力と出力を極力短く区切ることだ。
長く会話を続けるほど、論理崩壊の確率が指数関数的に高まっていく。
最近は「100万トークン対応」といった超長文対応モデルも登場しているが、実用的な推論精度は保てない。
モデルは直近の履歴に強い注意を向けるため、長大なコンテキストを持たせても初期設定は無視される。
長いコンテキストは「設定の忘却」を、長い連続生成は「論理の破綻」を招く。
たとえば、ブログ記事を書かせる場合、タイトルから結末までを一気に生成させるのは避けるべきだ。
構成案を作り、見出しごとに分けて生成させ、その都度人間がチェックを入れるといい。
こまめに区切りを入れ、AIの負担を減らす設計が必須となる。
入出力を短く保つことは、AIの性能を最大限に引き出すための基本中の基本だと言える。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
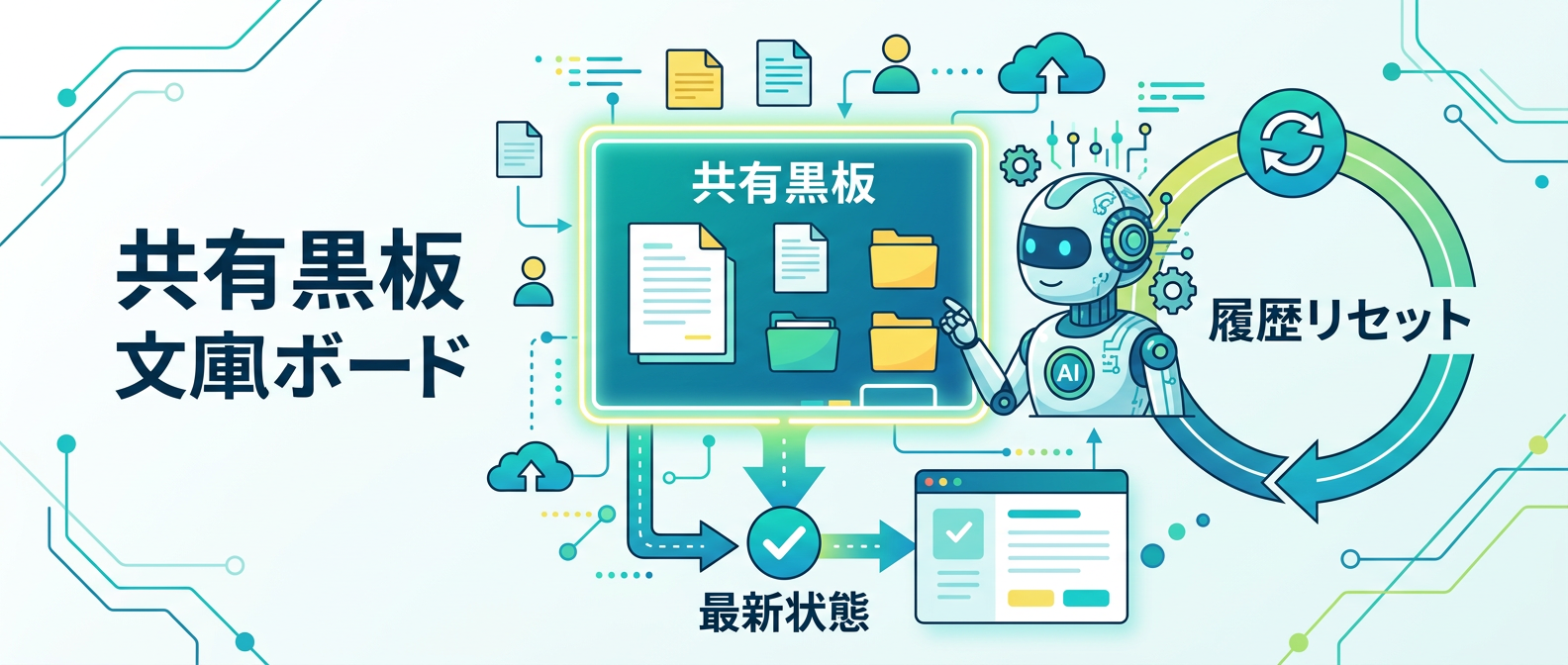
ステップ5:「共有黒板」と履歴リセットの導入
これが最も重要で効果的な対策だ。
長い会話履歴への依存を完全に捨て、重要な状態や決定事項を外部のテキストファイルに固定する。
これを共有黒板と呼ぶ。
タスクの区切りごとにチャット履歴を完全にリセットし、常に最新の黒板ファイルだけをAIに読み込ませる。
これにより、AIの推論が毎回クリアな状態で再スタートし、数学的な崩壊を防ぐことができる。
過去の雑談やノイズが一切含まれないため、AIは黒板に書かれた事実だけを元に精度の高い推論を行える。
たとえば、マークダウン形式でシステムの仕様書や現在の進捗を作り、それを毎回AIに渡す運用に変えるだけで劇的に精度が上がる。
履歴を引き継ぐのではなく、状態をアップデートして渡し直すという発想の転換が必要だ。
この手法を取り入れるだけで、長時間の作業でもAIの脱線を完全に防ぐことが可能になる。
ステップ6:外部検証と複数モデルの連携
単一のAIモデルで全てを完結させようとしないことも大切だ。
生成結果を別のAIに検証させるプロセスを組み込むといい。
計画を作るAIと、その結果をレビューするAIを分担させることで、エラーの連鎖を断ち切ることができる。
自分で書いた文章のミスには気づきにくいが、他人のミスならすぐに見つけられるのと同じ理屈だ。
また、推論時に内部で検証を行う最新のモデルを活用するのも有効な手段だ。
内部で複数の可能性を探索し、自ら間違いを訂正する仕組みを持っていれば、意味ドリフトの発生を大幅に抑えられる。
ただし、どんなに賢いモデルでも根本的な仕組みは同じなので、過信は禁物だ。
外部の黒板システムによる状態管理と、複数のAIによるクロスチェックを組み合わせるのが、最も確実なアプローチと言える。
システム全体でエラーを吸収する仕組みを作ることが、AI活用の最終形態だ。
しんたろー:
Claude Codeで毎日コード書いてる身からすると、共有黒板のアプローチが一番効果的だった。
理由はシンプルで、コンテキストをリセットするたびにAIの頭が冴え渡るのが実感できるからだ。仕様書をマークダウンでまとめて読み込ませるだけで、長時間の開発でも論理破綻が全く起きなくなった。
意味ドリフト対策の比較表
各対策手法の特徴とおすすめ度を比較表にまとめた。
状況に合わせて最適な手法を選ぶといい。
| 対策手法 | 期待できる効果 | 根本解決になるか | おすすめ度 |
| --- | --- | --- | --- |
| プロンプトの工夫 | 初期設定の強化 | ならない(延命のみ) | ★★☆☆☆ |
| ファインチューニング | 正解確率の底上げ | ならない(延命のみ) | ★★☆☆☆ |
| 入出力を短く区切る | エラー蓄積の防止 | なる | ★★★★☆ |
| 共有黒板+履歴リセット | 推論の完全な再正規化 | なる | ★★★★★ |
| 複数モデルでの検証 | エラー連鎖の遮断 | なる | ★★★★☆ |
つまずきポイント3選
初心者がハマりやすい罠を3つ紹介する。
これらを避けるだけで、AIの活用スキルは一段階上がるはずだ。
- 1つのチャットで全部終わらせようとする
一番やりがちなミスだ。
AIは賢いから何でも覚えていてくれると勘違いしてしまう。
タスクが変わったら、勇気を出して新しいチャットを立ち上げよう。
- 「絶対に忘れないで」とプロンプトに書き込む
感情的に指示を出してもAIの数学的な構造は変えられない。
文字数を無駄に消費するだけで、むしろ他の重要な指示を押し出す原因になる。
指示を増やすより、履歴を消す方が圧倒的に効果的だ。
- 黒板ファイルに情報を詰め込みすぎる
共有黒板が便利だからといって、過去の全履歴をファイルに書き込んでは意味がない。
必要なのは「現在の最新状態」と「最終決定事項」だけだ。
黒板は常にシンプルに保つことを心がけるといい。

よくある質問(FAQ)
Q1: システムプロンプトで「絶対に忘れないで」と強く指示すれば防げる?
防げない。AIの内部では、システムプロンプトなどの絶対のルールも、ユーザーの雑談などの会話履歴も、区別なく次の一文字を予測するための等価なデータとして扱われる。会話が長くなると、Softmax Crowdingという数学的な現象が起きる。これにより、初期設定への注意力が直近の会話履歴のノイズに押し潰されてしまう。どんなに強く指示を書いても、物理的に設定が埋もれてしまうのは避けられない。根本的な解決には、履歴をこまめにリセットする運用が必要だ。
Q2: ファインチューニングで専門知識を学習させれば意味ドリフトは無くなる?
無くならない。ファインチューニングは特定の出力の正解確率を高める効果はあるが、AIが確率分布から文字を選ぶ以上、不正解を選ぶ確率を数学的にゼロにすることはできない。正解確率が99.9%でも、残り0.1%のハズレを引いた瞬間、その微細な間違いが次の入力として固定される。これが自己回帰によって再帰的にフィードバックされることで、エラーが雪だるま式に蓄積し、最終的に意味ドリフトを引き起こす。ファインチューニングはドリフトを遅らせるだけで、根本治療にはならない。
Q3: 100万トークン対応などの超長文対応モデルなら、長い会話でも大丈夫?
カタログスペック上は入力可能でも、実用的な論理推論の精度は保てない。最新の研究でも、コンテキストが長くなるほど論理的推論能力が急激に崩壊する現象が実証されている。モデルは位置的・意味的に近い直近の履歴に強い注意を向けるため、長大なコンテキストを持たせても初期の重要な設定は無視されがちだ。長いコンテキストは設定の忘却を招き、長い生成ステップは論理の破綻を招く。そのため、入出力を短く区切るのが鉄則となる。
Q4: 記事にある「共有黒板」とは具体的にどういうこと?
チャットの履歴をそのまま引き継ぐのではなく、決定事項や現在の状態を一つのテキストファイルにまとめ、それを黒板として扱う手法だ。AIとの対話が長くなると、履歴の中に微小なノイズやズレが蓄積し、それが次の推論を狂わせる原因になる。そこで、タスクの区切りごとにチャット履歴を完全にリセットし、常に最新の黒板ファイルだけをAIに読み込ませて推論を再開させる。これにより、AIの確率分布が鋭く再正規化され、論理の脱線やハルシネーションを防ぐことができる。
Q5: 推論時に計算を行う最新モデルを使えば、この問題は解決する?
推論時に内部で探索と検証を行うモデルは、意味ドリフトの抑制に非常に有効だ。事前学習モデルを巨大化させるより、推論時に計算資源を使って検証を行う方が性能向上に寄与することが証明されている。しかし、根本的な自己回帰の仕組みは同じであるため、極端に長いコンテキストや無制限の連続生成ではいずれ限界が来る。最新モデルの能力を過信せず、外部の黒板システムと併用するのが最も確実なアプローチと言える。
推論時に計算を行う最新モデルはかなり良さそうだ。
ただ、1人開発でコストを抑えつつ安定稼働させるなら、やはり共有黒板とClaude Codeの組み合わせが今のところ最強の布陣だと感じている。
まとめ
今回は、AIの意味ドリフト対策について解説した。
まとめると以下のようになる。
- 意味ドリフトはAIの数学的な宿命
- プロンプトや学習では根本解決しない
- 入出力を短く区切り、こまめに検証する
- 共有黒板を作り、履歴を毎回リセットする
AIは魔法の杖ではなく、数学的な確率で動くツールだ。
その限界を正しく理解し、人間側が適切にコントロールする仕組みを作ることが成功の鍵となる。
まずは、長すぎるチャット履歴を捨てて、共有黒板の運用から始めてみるといい。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る

ThreadPost 代表 / SNS自動化の研究者
ThreadPost運営。Claude Codeで1人SaaS開発しながら、AIツール・活用術を初心者向けにわかりやすく紹介。
@shintaro_campon関連記事

Google公式発表。Gemini 3.1 ProでAI開発はどう変わるのか。単なるチャットボットから脱却する理由

【2026年版】最新AIエージェント構築ツール3選|1人SaaS開発者が本気で比較

Anthropic公式が発表。DeepSeek等にClaudeが1600万回不正抽出された理由とAI開発への影響

【2026年版】最新AIエージェント比較3選|1人SaaS開発者が推す最強環境

【2026年版】Cursorで実現するAI駆動開発Tips10選|1人SaaS実践者が厳選

【2026年版】ChatGPT・Gemini画像生成AI5選|1人開発者が実務で使う
人気の記事

【2026年覇権交代】1億4,150万人が選ぶ「最強テキストSNS」と2つの高反応時間帯

エンゲージメント2倍!7100万件のデータから導くベスト投稿時間3つの法則

月収18万で廃業寸前だった大学中退フリーランスが「対象を絞っただけ」のメルマガ配信ツールで年商60億円を創った裏側

巨大企業の歯車として消耗していた2人の会社員が『ただの要望掲示板』を作ったら年商4.5億円。

1回25ドルのトークン消費。Claude Codeのマルチエージェント化が迫る、個人開発のハイブリッド運用。
