
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
意図の言語化が新たなボトルネックになる
AIにコードを書かせるコストが10分の1に下がった。
でも、開発速度はどこかで必ず頭打ちになる。
理由はシンプルだ。
AIに「何をどう作るか」を伝えるコンテキスト設計が、新たなボトルネックになっている。
単にプロンプトを投げるだけのアプローチは通用しない。
今は、人間の20年分の開発知見をAIのワークフローに移植するフェーズに入っている。
意図をどう構造化し、どうAIにリレーさせるか。
これが今後のチームの生産性を完全に二分する。
AIへの指示ファイルは開発プラクティスの再発明
ここ1年で、AIへの指示ファイルが急増した。
「CLAUDE.md」や「.cursor/rules」など、ツールごとに名前は違う。
でも、長年ソフトウェア開発をやってきた人なら既視感があるはずだ。
これらは要件定義書であり、オンボーディング資料であり、ランブックだ。
AIコーディングツールの設計思想は、人間が20年かけて積み上げた開発プラクティスの再発明に他ならない。
各ツールの指示設計は、新メンバーに最初に何を渡すかの違いに似ている。
人間の開発プラクティスとAI指示ファイルの対応関係は以下の通りだ。
- 要件定義書: AIに仕様と受け入れ基準を構造化して渡す
- オンボーディング資料: コードから推測できない暗黙知を言語化する
- コーディング規約: プロジェクトのルールをフラットに記述する
- ランブック: タスク実行のステップを明示的に定義する
各AIツールが提供する指示の渡し方を比較すると、設計思想の違いが明確になる。
Kiroは仕様書から入るアプローチをとる。
要件を構造化して、受け入れ基準を明確にしてから実装に入る。
Requirements-FirstとDesign-Firstの2つのワークフローを提供する。
Claude Codeは暗黙知の言語化を重視する。
CLAUDE.mdにコードから推測できない永続的なコンテキストを書く。
Cursorはルールだけ渡して自由にやらせる。
.cursor/rulesにプロジェクトルールをフラットに書き、エージェントの判断に委ねる。
Devinは手順書通りにやらせる。
Playbooksでステップを明示的に定義し、タスク実行のフローを人間側が制御する。
どれが正解というわけではない。
チームの性質や業務の特性に応じた設計の違いだ。
ここで起きている失敗パターンも、人間のチーム開発と全く同じだ。
設計ドキュメントなしでプロジェクトを始めると属人化する。
AIの場合、セッションをまたげばコンテキストが消える。
毎回同じ説明を繰り返し、それでも違う出力が返ってくる。
これはドキュメントがなければ暗黙知は蒸発するという、10年以上前から言われてきた古典的な課題だ。
もう一つの失敗は情報過多だ。
MCPサーバーを10個入れたら応答品質が崩壊したという話をよく聞く。
ツール定義だけでコンテキストウィンドウを圧迫し、AIが結果を読み飛ばし始める。
ある事例では、ミーティングの文字起こしを転送するだけで追加5万トークンを消費した。
これは新人の初日にSlackの30チャンネルに招待して機能停止させるのと同じ構造だ。
人間でもAIでも、処理可能な情報量には限界がある。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
しんたろー:
MCPサーバー入れすぎてClaudeがポンコツ化する現象、すごく気になる。
人間もAIもキャパオーバーの挙動は完全に一致してる。
僕も気をつけないと、いつの間にかトークンだけ爆食いする設定を作ってしまいそう。

意図の抽出すらAIに自動化させる最前線
コンテキストの設計がボトルネックになる。
では、そのコンテキストを誰が作るのか。
人間が毎回PRD(製品要求仕様書)やタスク分割を書くのには限界がある。
そこで先進的なチームは、意図の抽出と構造化自体をAIにやらせ始めている。
最近のClaude Codeの活用事例を見ると、その進化のスピードが凄まじい。
v2.1.0からv2.1.74までの間に60回のバージョンリリースがあった。
実に869個のリリースアイテムが含まれている。
その中で特に注目されているのが、Agent Teamsとカスタムスキルの活用だ。
あるチームは、機能の説明を入力するだけでPRDと開発タスクファイルを自動生成する仕組みを作った。
Claude Codeのカスタムスキル(旧カスタムスラッシュコマンド)を使っている。
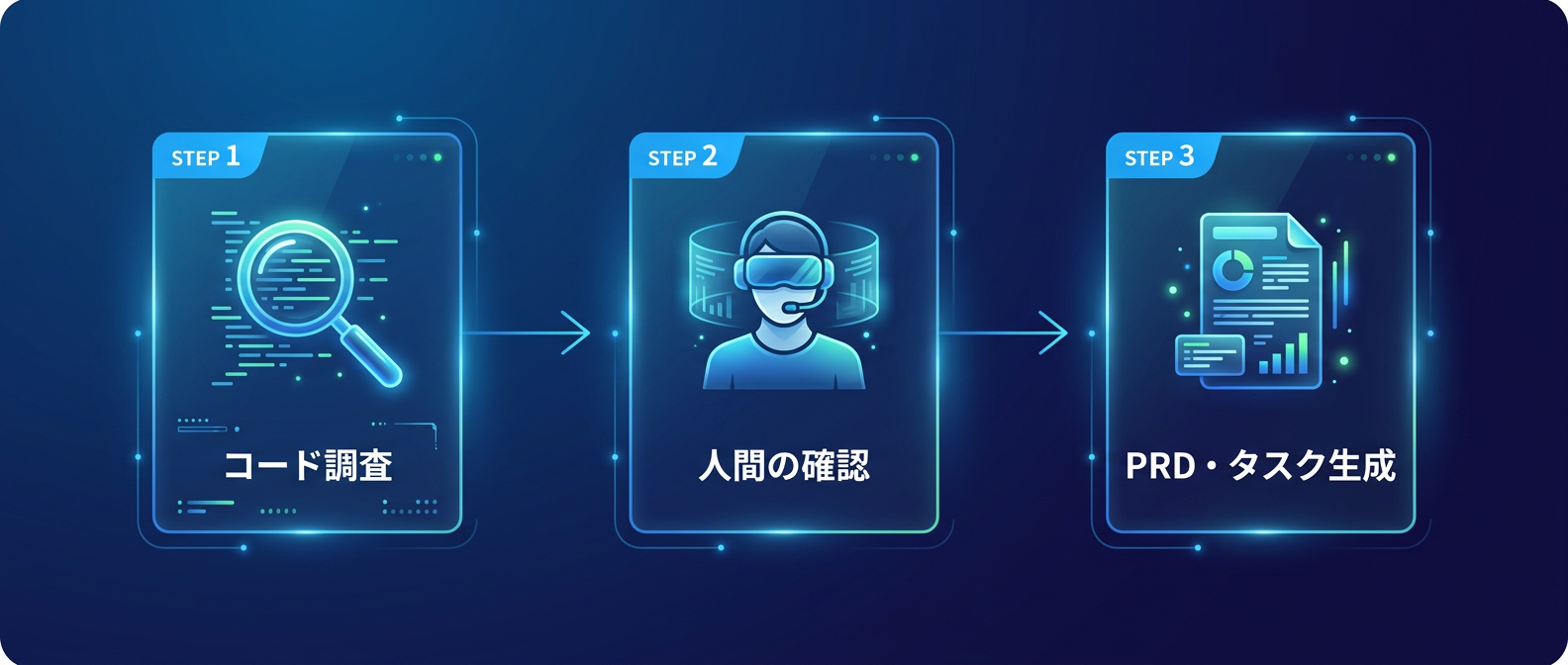
6ステップで機能開発の初期フェーズを自動化する。
いきなりコードを書かせるのではない。
まず既存コードの調査を行わせる。
関連するドメインモデルやAPI定義を読ませる。
次にPRDを生成し、タスクを分割する。
このスキルで自動化できる初期フェーズは以下の通りだ。
- 関連する既存ドキュメントの検索と特定
- 影響が想定されるコードリポジトリの事前調査
- ユーザーとの対話的な影響範囲のすり合わせ
- テンプレートに基づく技術実装PRDの生成
- アーキテクチャ図やフロー図の自動出力
- レビュー可能な粒度でのPR分割戦略の立案
ここで、AIに一気に最終成果物を出力させない仕組みが機能する。
中間に人間の確認ゲートを設けている。
AIが既存コードを調査した後、影響レイヤーや関連ドメインが合っているかユーザーに対話形式で確認する。
AskUserQuestionという仕組みだ。
これにより、AIの見当違いな設計を防ぐ。
さらに、調査方法も使い分けている。
複数ドメインにまたがる大規模な調査は専用の調査エージェントに任せる。
特定のファイルの確認で済む小規模な調査は直接行う。
適材適所でエージェントを動かすことで、コンテキストの崩壊を防いでいる。
ThreadPostの開発でも、要件定義からタスク分割までのフローをClaude Codeのスキルに落とし込めたら相当楽になりそう。
今は僕が頭の中でやってる「この機能ならあの辺のファイルに影響するな」って当たりをつける作業。
これを自動化できたら、一人開発の限界突破できそうだな。でも結局、僕の頭の中の暗黙知を言語化する作業で1日終わりそう。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
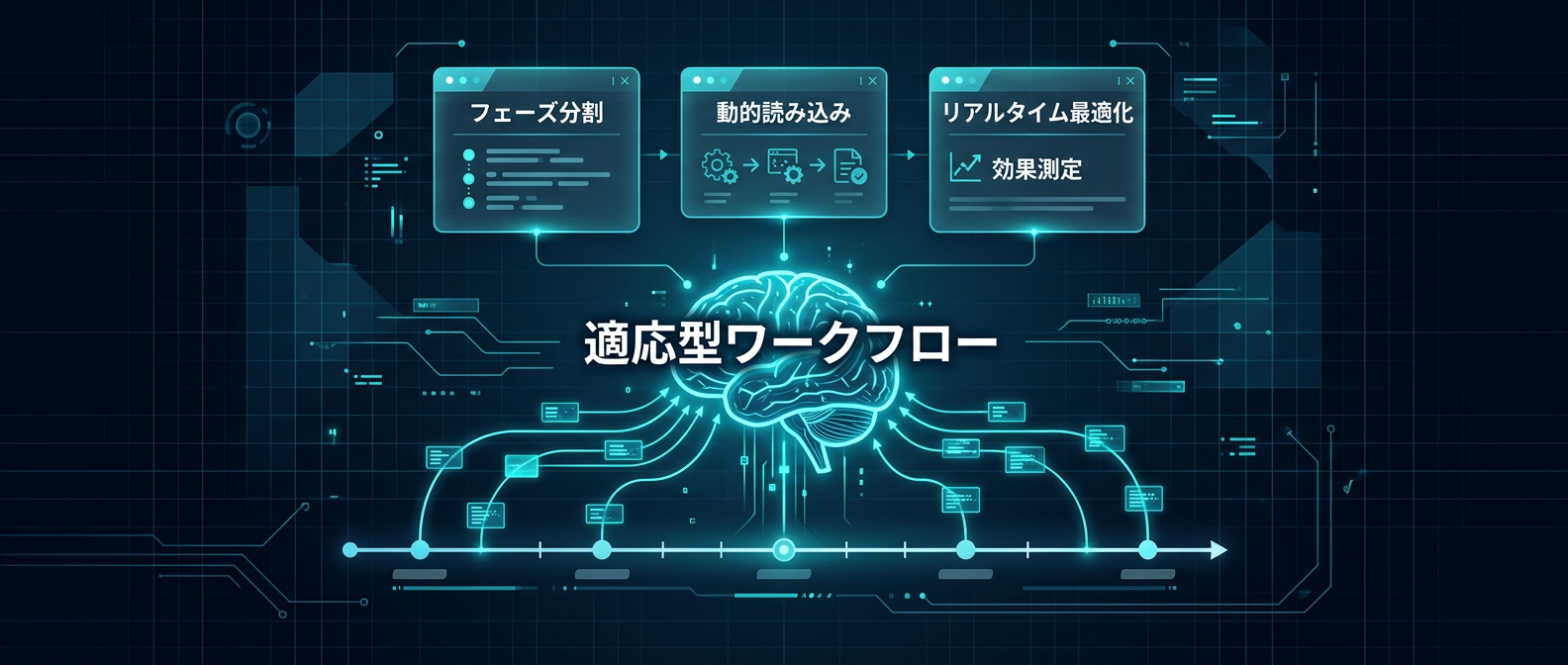
適応型ワークフローによるコンテキストの最適化
巨大なリポジトリでAIにコンテキストを渡す際、常に全情報を渡すのは悪手だ。
トークンを浪費し、AIが混乱する。
そこで適応型ワークフローの考え方が浮上する。
必要な情報を、必要なタイミングで動的に読み込ませる。
ある実践事例では、AI-DLC(AI主導の開発ライフサイクル)という手法が紹介されている。
フェーズごとに該当するルールファイルだけを読み込む仕組みだ。
事前の定義済みワークフローで制御するのではなく、ステアリングポリシーで動的に制御する。
情報過多を防ぐための適応型ワークフローのポイントは以下の通りだ。
- 全情報を一度に渡さずフェーズごとに分割する
- 必要なルールファイルだけを動的に読み込む
- 大規模調査と小規模調査でエージェントを使い分ける
- AIの思考プロセスを人間に説明させるステップを挟む
AIに実装やレビューを行わせる前に、まず調査を行わせる。
そして、その観点を説明させる。
これにより、AIの思考プロセスがブラックボックス化するのを防ぐ。
人間が可読性や理解を保ったまま、AIの出力を検証できる。
AIが進化しても、出力が平均に寄ってしまうという課題もある。
よくあるデザインや設計になってしまう現象だ。
これに対するアプローチとして、AIに渡すコンテキストを意図的に偏らせる手法がある。
入力の方向性をコントロールすることで、出力の独自性を出す。
僕らの開発においても、単にAIにコードを書かせるフェーズは終わった。
AIが迷わず動けるためのコンテキストをどう設計するか。
そして、そのコンテキスト設計自体をどうAIに組み込むか。
これが今後のチーム生産性を分ける鍵になる。
必要なルールだけ動的に読み込ませるアーキテクチャ、理にかなってる。
全部入りの巨大なプロンプトは保守も地獄だしね。
状況に応じてAIのOSを切り替えるみたいな感覚、今後のスタンダードになりそう。まあ、そのOSの切り替え設定を書くのにまた頭を悩ませるんだけど。
Claude Codeの高度な活用に関するFAQ
Q1: Claude Codeのカスタムスキルはどのように作成してプロジェクトに導入するのですか?
Claude Codeのカスタムスキルは、プロジェクト内の特定のディレクトリにマークダウンファイルを配置するだけで定義できる。
ファイル内にコマンドの説明、引数の扱い、実行してほしいプロンプトのステップを自然言語で記述する。
例えば「既存コードの調査→ユーザー確認→ファイル生成」といった手順だ。
これをGitリポジトリにコミットしてチームで共有する。
全員が同じ手順でAIにタスクを依頼できるようになる。
属人化を防ぎつつプロジェクト固有の開発フローを自動化できる。
Q2: AIにPRDやタスク分割を作らせる際、見当違いな設計になるのを防ぐにはどうすればよいですか?
AIに一気に最終成果物を出力させず、中間に人間の確認ゲートを設けることが必須だ。
AIが既存コードやドキュメントを調査した後、いきなりPRDを書かせるのは危険だ。
「影響レイヤーや関連ドメインはこれで合っているか?」をユーザーに対話形式で確認するステップを挟む。
また、AIに実装やレビューを行わせる前に、まず調査を行わせ、その観点を説明させる。
AIの思考プロセスを可視化する。
人間が軌道修正しやすい設計にすることがベストプラクティスだ。
Q3: 巨大なリポジトリでAIにコンテキストを渡す際、トークン制限や情報過多を防ぐコツは?
必要な情報を必要なタイミングで動的に読み込ませる適応型ワークフローが有効だ。
MCPサーバーなどで無差別に情報を与えるとAIは混乱し、トークンも浪費する。
対策として、フェーズごとに該当するルールファイルだけを読み込ませる仕組みを作る。
大規模な調査は専用のエージェントに任せ、小規模なら直接調査するといった使い分けも推奨される。
常に全情報を渡すのではない。
タスクの粒度に合わせてコンテキストを絞り込む設計が不可欠だ。
まとめ
AIによるコード生成の先にあるのは、意図の構造化とコンテキストの動的制御だ。
人間の知見をAIのワークフローにどう移植するかが、今後の開発速度を決定づける。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る

ThreadPost 代表 / SNS自動化の研究者
ThreadPost運営。Claude Codeで1人SaaS開発しながら、海外AI最新情報を開発者目線で発信中。
@shintaro_campon関連記事

Google公式発表。Gemini 3.1 ProでAI開発はどう変わるのか。単なるチャットボットから脱却する理由

【2026年版】最新AIエージェント構築ツール3選|1人SaaS開発者が本気で比較

Anthropic公式が発表。DeepSeek等にClaudeが1600万回不正抽出された理由とAI開発への影響

【2026年版】最新AIエージェント比較3選|1人SaaS開発者が推す最強環境

【2026年版】Cursorで実現するAI駆動開発Tips10選|1人SaaS実践者が厳選

【2026年版】ChatGPT・Gemini画像生成AI5選|1人開発者が実務で使う
人気の記事

【2026年覇権交代】1億4,150万人が選ぶ「最強テキストSNS」と2つの高反応時間帯

エンゲージメント2倍!7100万件のデータから導くベスト投稿時間3つの法則

月収18万で廃業寸前だった大学中退フリーランスが「対象を絞っただけ」のメルマガ配信ツールで年商60億円を創った裏側

巨大企業の歯車として消耗していた2人の会社員が『ただの要望掲示板』を作ったら年商4.5億円。

1回25ドルのトークン消費。Claude Codeのマルチエージェント化が迫る、個人開発のハイブリッド運用。
