
AI開発をしていて「ChatGPTやClaudeが過去の会話をすぐ忘れてしまう」と悩んだことはありませんか?
結論から言うと、AIに「長期記憶」を持たせることでこの問題は劇的に解決します。
今回は、僕のような1人SaaS開発者でも今日から始められる、RAG(検索拡張生成)の基礎から、最新のLLMメモリ実装までの4つのステップをわかりやすく解説します。
読者は「結局何から始めればいいの?」と疑問を抱いているはずです。
安心して読み進めてください。初心者でも大丈夫なように、具体例を交えてステップバイステップで教えます。一緒にAIを賢く育てていきましょう!
このガイドを実践するための前提知識として、基本的なプログラミングの知識(TypeScriptやPythonなど)と、OpenAIやAnthropicのAPIキーが必要です。
また、データを保存するためのデータベース(SQLiteなど)の準備もしておくとスムーズです。
PCとエディタさえあれば、今日からすぐに開発をスタートできます。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
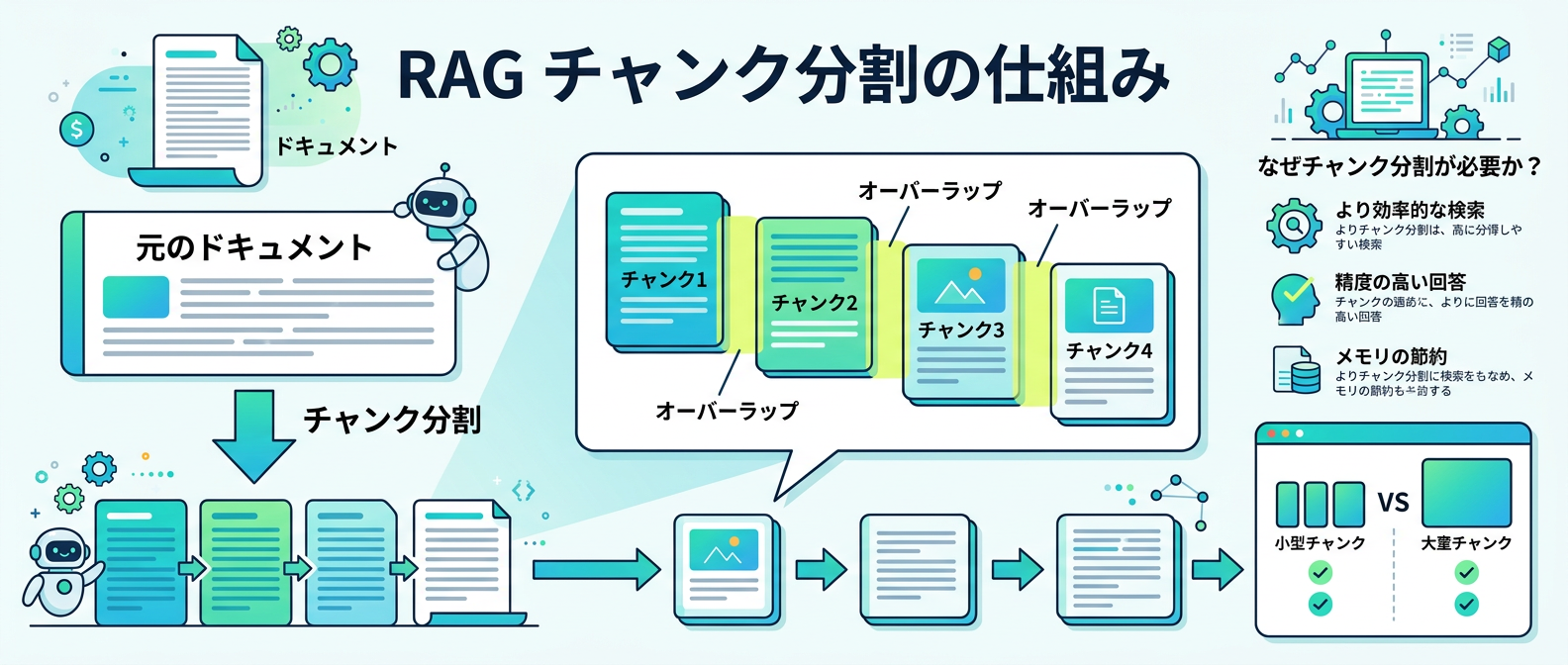
ステップ1:RAGの基本構築と「チャンク化」をマスターする
AIに外部データを読み込ませる第一歩が、RAG(検索拡張生成)の構築です。
LLMには一度に入力できる文字数(コンテキストウィンドウ)に制限があるため、長いドキュメントをそのまま渡すことはできません。
そこで必要になるのが、テキストを細かく分割する「チャンク化」という作業です。
たとえば、Wikipediaの長い記事をAIに読み込ませたいとします。
このとき、500文字程度の短い塊(チャンク)に切り分けてから、ベクトルデータベースと呼ばれる専用の保存場所に格納します。
ここで重要なのが、前後の文脈が途切れないように、チャンク同士を少し重複させる「オーバーラップ」というテクニックです。
これを行うことで、AIが質問に答える際に必要な情報を正確に見つけ出しやすくなります。
TypeScriptとLanceDBなどのツールを使えば、ローカル環境でも簡単にベクトル検索の仕組みを作ることができます。
まずはシンプルなテキストファイルを使って、データを分割し、保存するサイクルを体感してみるのがおすすめです。
この基礎的な実装方法は、TypeScriptとLanceDBの組み合わせで十分に実現できる。
ステップ2:検索メモリ(GAM-RAG)で速度と精度を上げる
基本のRAGができたら、次は検索の効率化です。
AIエージェントを使って何度も検索を繰り返すと、精度は上がりますが、時間とトークン(APIの利用枠)を大量に消費してしまいます。
そこで活躍するのが、検索結果を記憶して次回に活かす「GAM-RAG」という最新の手法です。
この仕組みの面白いところは、単に文章を保存するだけでなく、その文章が「どれくらい役に立ったか」という信頼性のスコアを一緒に記憶する点です。
たとえば、ある検索でAIが「この文章は回答にすごく役立った」と判断したら、その文章のスコアを上げます。
逆に、的外れだった文章のスコアは下げていきます。
これを繰り返すことで、AIは過去の経験から「どの情報が本当に使えるか」を学習します。
次回以降の検索では、スコアの高い有用な情報を優先的に引き出せるようになるため、無駄な検索ステップを省き、圧倒的なスピードと高精度を実現できるのです。
このフィードバックのループが今後のAI開発の鍵になる。
ステップ3:LLMに人間の脳のような「長期記憶」を実装する
ここからが本番です。
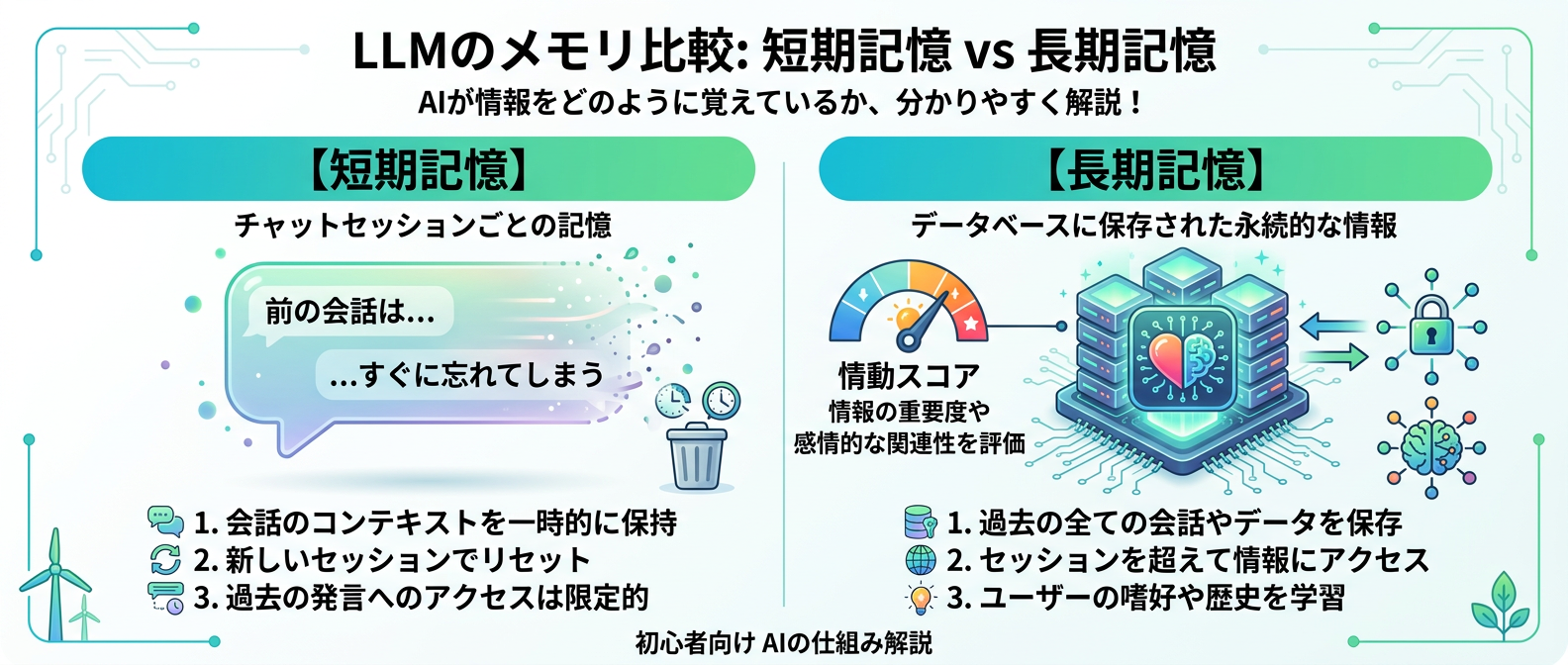
LLMの短期記憶(チャット画面を開いている間だけの記憶)の限界を超え、人間の脳を模した長期記憶システムを作ります。
僕が普段使っているClaude CodeなどのAIツールも、こうした高度なコンテキスト保持の仕組みによって、まるで長年の相棒のように振る舞ってくれるようになります。
人間の脳は、すべての出来事を平等に記憶するわけではありません。
「驚いた!」「これは重要だ!」と感情が動いた(情動が伴った)出来事ほど、強く記憶に定着します。
これをシステムで再現するために、入力されたテキストから「重要度」や「驚き」などの情動を判定し、記憶に重み付けをしてSQLiteなどのデータベースに保存します。
そして、AIが記憶を思い出す(検索する)ときには、単なるキーワードの一致だけでなく、現在の気分や時間帯、直前の会話の文脈などを掛け合わせて、最適な記憶を引き出します。
これにより、同じ質問をしても、その時の状況に応じた人間らしい自然な回答が返ってくるようになります。
脳のメカニズムを機能的に模倣するこのアプローチは、非常にワクワクする領域だ。
しんたろー:
Claude Codeで毎日コード書いてる身からすると、この情動ベースの記憶システムは本当に使いやすかった。
理由はシンプルで、エラーに詰まってイライラしている時の文脈まで汲み取って、過去の似たようなバグ解決の記憶をスッと出してきてくれるから。ただの検索ツールが「相棒」に変わる瞬間を味わえます。
ステップ4:LLM-as-a-Judgeでシステムを自動評価する
RAGや記憶システムを構築したら、最後に「それが本当に正しく動いているか」を評価する必要があります。
ここで使うのが、AI自身に採点者を任せるLLM-as-a-Judgeという手法です。
人間がいちいち回答を読んでチェックするのは大変なので、AIに評価基準を渡して自動で採点させます。
結論から言うと、この自動評価は「同じモデルを使って相対的に比較する」のであれば、非常に安定していて実用的です。
たとえば、「プロンプトA」と「プロンプトB」のどちらが良い回答を出せるかを比べる場合、AIは毎回ブレることなく正確な優劣をつけてくれます。
ただし、AIが事実とは異なる嘘をつく「ハルシネーション」を厳密に見抜きたい場合は注意が必要です。
1つのAIモデルだけだと判定基準が偏ることがあるため、複数の異なるモデルを組み合わせて評価させるなどの工夫が求められます。
実際のところ、単一モデルでの評価は偏りが出やすい。複数モデルを組み合わせることで、スコアの安定性が格段に上がる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
しんたろーの体験:実際に長期記憶を活用してみて
ここまで4つのステップを解説してきましたが、僕自身が日々の開発でClaude Codeを活用しているリアルな所感をお伝えします。
僕はClaude Code一択。理由は、コンテキスト理解の精度が段違いだから。
Claude Codeを本格導入してからは開発スピードが2倍以上に跳ね上がった。数週間前に書いた複雑なデータベース設計の背景を、AIが「あの時のあの条件ですね」と文脈を汲み取ってコードを提案してくれる。毎回前提条件を説明するストレスがゼロになるのは最高だ。
最初は「データベースの準備など、環境構築が面倒だ」と感じる人も多いですが、一度仕組みを作ってしまえば、あとはAIが自動的に学習を深めてくれます。
特に、ステップ2で紹介した検索結果のスコア化と、ステップ3の情動による重み付けを組み合わせると、AIの回答の「的確さ」が段違いに上がります。
初心者の方も、まずはローカル環境で小さなテキストファイルから試してみてください。
初心者がハマりやすい3つのつまずきポイント
RAGやメモリ実装を始める際、僕も最初は何度も失敗しました。
ここでは、初心者が特にハマりやすいポイントを3つ紹介します。
- チャンクサイズを大きくしすぎる
「面倒だから」とテキストを大きすぎる塊で分割してしまうと、AIが本当に必要な情報を見つけられなくなります。
まずは500文字程度の小さめのサイズから始め、必ずオーバーラップ(重複部分)を持たせましょう。
- ベクトル検索のスコアだけで満足してしまう
単純な類似度検索だけだと、「キーワードは同じだけど文脈が違う」情報ばかり拾ってしまい、精度が頭打ちになります。
ステップ3で解説したような、情報の「新しさ」や「重要度」を掛け合わせる仕組みを取り入れるのがコツです。
- 自動評価の基準を曖昧にする
AIに採点させる際、「良い回答か評価して」といったざっくりした指示だと、スコアが毎回ブレてしまいます。
「この3つのキーワードが含まれているか」「文字数は適切か」など、具体的な採点基準をプロンプトに明記することが重要です。
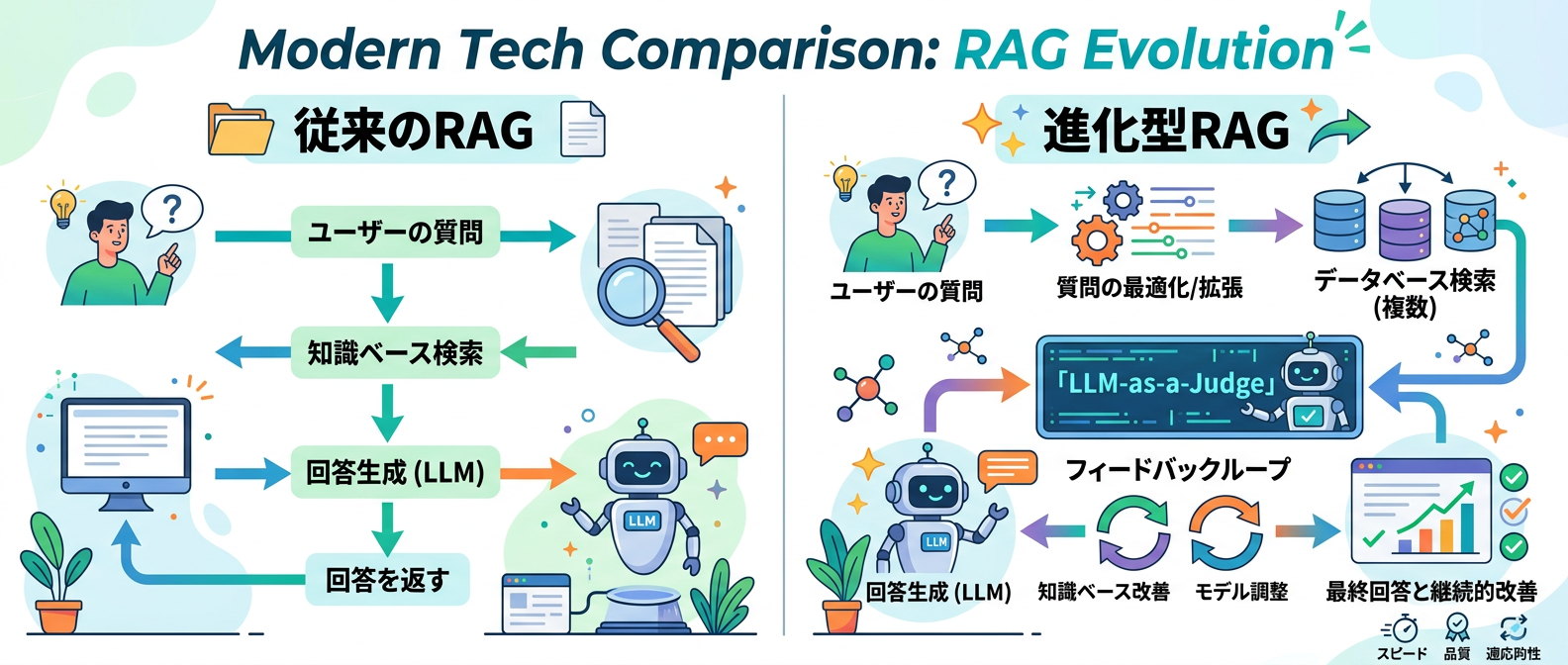
比較表:RAGの進化と特徴
ここで、従来のシンプルなRAGと、今回紹介した高度なRAG(メモリ実装型)の違いを比較表にまとめました。
自分のプロジェクトに合った手法を選んでみてください。
| 手法・システム | 検索の仕組み | 記憶の持ち方 | おすすめ度 | 開発の難易度 |
| :--- | :--- | :--- | :--- | :--- |
| 従来のRAG | 単純なベクトル類似度検索 | 記憶なし(毎回リセット) | ★★☆☆☆ | 低(初心者向け) |
| GAM-RAG | 信頼性スコアに基づく検索 | 検索結果の有用性を数値で蓄積 | ★★★★☆ | 中 |
| 情動的長期記憶 | 文脈・気分・重要度の掛け合わせ | 脳を模倣した永続的な記憶 | ★★★★★ | 高 |
よくある質問(FAQ)
RAGやLLMのメモリ実装について、初心者が気になる疑問をまとめました。
Q1: RAGにおける「チャンク化」とは何ですか?なぜ必要なのですか?
チャンク化とは、長いテキストデータをAIが処理しやすいように数百文字程度の短い塊に分割することです。
AIには一度に入力できる文字数に制限があるため、本一冊のような長い文章をそのまま渡すことができません。
適切なサイズに分割し、前後の文脈が途切れないように一部を重複させることで、質問に対して最も関連性の高い部分だけを正確に検索してAIに渡すことが可能になります。
Q2: LLMの「短期記憶」と「長期記憶」の違いは何ですか?
LLMの短期記憶は「コンテキストウィンドウ」と呼ばれ、1回のチャット画面を開いている間だけ保持される情報のことです。画面を閉じると全てリセットされます。
一方、長期記憶は、過去の会話や外部データをデータベースに永続的に保存し、必要に応じて引き出す仕組みです。
長期記憶を実装することで、日をまたいだ会話でも過去の文脈やあなたの好みを踏まえた回答が可能になります。
Q3: RAGの検索速度が遅い場合、どのように改善すればよいですか?
検索速度の改善には、検索結果のフィードバックを蓄積する「GAM-RAG」のようなメモリ手法が非常に有効です。
過去の検索でAIが「役立つ」と判断した文章の信頼性スコアを記憶しておくことで、次回からは無駄な検索ステップを省き、有用な情報を一瞬で取得できるようになります。
また、データベースのインデックス設定を見直すことも速度向上につながります。
Q4: LLMに人間の脳のような「情動」を持たせるメリットは何ですか?
入力されたテキストから「驚き」や「重要度」などの情動を判定して記憶に重み付けをすることで、より人間らしい自然な記憶の引き出しが可能になります。
たとえば、重要だと判断された情報は優先的に思い出されやすくなり、現在の気分や直前の会話の文脈に合わせて回答のニュアンスが変化します。
これにより、単なる辞書のようなAIから、文脈に寄り添う相棒のようなAIへと進化します。
Q5: 構築したRAGの回答精度はどのように評価すればよいですか?
AI自身を評価者として使う「LLM-as-a-Judge」という手法が最も効率的です。
人間が手動で確認する代わりに、AIに明確な採点基準を与えて自動でテストさせます。
単一のAIモデルを使って「AとBどちらが良いか」を比較する場合は非常に安定した結果が出ます。
ただし、嘘(ハルシネーション)を厳密にチェックしたい場合は、複数のAIモデルを組み合わせて評価の偏りを防ぐのがおすすめです。
まとめと次の一歩
今回は、RAGの基本構築から、検索の効率化、LLMへの長期記憶の実装、そして自動評価までの4つのステップを解説しました。
まとめると以下のようになります。
- ステップ1: データを細かく分割(チャンク化)してAIに読み込ませる基礎を作る
- ステップ2: 検索結果の信頼性を記憶させ、次回以降の速度と精度を上げる
- ステップ3: 情動や重要度で記憶に重み付けをし、人間らしい長期記憶を持たせる
- ステップ4: AI自身にテスト(自動評価)をさせて、システムの品質を保つ
最初は難しく感じるはずですが、まずはローカル環境で簡単なテキストを分割して検索させるところから始めてみましょう。
AIが過去の文脈を理解して的確な答えを返してくれた時の感動は、一度味わうと病みつきになります。
RAGのチャンク化で工夫している点や、LLMのメモリ実装で直面した課題について、SNSで教えてください!
日々の開発や発信活動を効率化したい方は、以下のツールもチェックしてみてくださいね。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る

ThreadPost 代表 / SNS自動化の研究者
ThreadPost運営。Claude Codeで1人SaaS開発しながら、AIツール・活用術を初心者向けにわかりやすく紹介。
@shintaro_campon関連記事

Google公式発表。Gemini 3.1 ProでAI開発はどう変わるのか。単なるチャットボットから脱却する理由

【2026年版】最新AIエージェント構築ツール3選|1人SaaS開発者が本気で比較

Anthropic公式が発表。DeepSeek等にClaudeが1600万回不正抽出された理由とAI開発への影響

【2026年版】最新AIエージェント比較3選|1人SaaS開発者が推す最強環境

【2026年版】Cursorで実現するAI駆動開発Tips10選|1人SaaS実践者が厳選

【2026年版】ChatGPT・Gemini画像生成AI5選|1人開発者が実務で使う
人気の記事

【2026年覇権交代】1億4,150万人が選ぶ「最強テキストSNS」と2つの高反応時間帯

エンゲージメント2倍!7100万件のデータから導くベスト投稿時間3つの法則

月収18万で廃業寸前だった大学中退フリーランスが「対象を絞っただけ」のメルマガ配信ツールで年商60億円を創った裏側

巨大企業の歯車として消耗していた2人の会社員が『ただの要望掲示板』を作ったら年商4.5億円。

1回25ドルのトークン消費。Claude Codeのマルチエージェント化が迫る、個人開発のハイブリッド運用。
