
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
1ファイルあたり1,762トークンの浪費
1ファイルあたり1,762トークン。
これがルール設定のミスで毎回消費される数字だ。
ルールを全部CLAUDE.mdに詰め込む運用は限界を迎えている。
AIの暴走とトークン浪費の引き金になる。
ルールが多すぎるとAIは指示を忘れる。
無関係なファイルで過剰にルールを適用して処理が止まる。
そして数万トークンが空に消えていく。
pathsを使った遅延ロードが解決策となる。
ルール崩壊のメカニズムとトークン浪費の真実
Claude Codeの運用において、CLAUDE.mdへのルールの詰め込みが事故を引き起こしている。
コーディング規約や設定ファイルの変更手順を単一ファイルに追記する。
コミットメッセージのフォーマットも同じ場所に書く。
結果としてAIがルールを無視し始める。
「変更前に確認して」と書いた設定ファイルがデフォルト値でリセットされる。
Dockerの再ビルドが必要な変更で、コードだけ直して完了報告をしてくる。
これらは本番運用で実際に起きている事故だ。
逆に明確な指示を出したのに「どのような作業をご依頼いただけますか?」と処理が止まる。
曖昧な指示の時だけ確認するというルールが、すべての指示に過剰適用された結果だ。
デフォルト2分のタイムアウトを知らずに重いビルドを走らせ、中途半端な状態で処理が止まる事故も起きている。
これはAIの気まぐれではなく構造的な問題だ。
CLAUDE.mdはあくまでコンテキストに過ぎない。
「この部屋では静かにして」という壁の貼り紙と同じだ。
情報量が膨大になると、AIは貼り紙の存在自体を忘れてしまう。
LLMの特性上、コンテキストが長くなればなるほど中間の情報は無視されやすくなる。
これを「Lost in the Middle」現象と呼ぶ。
ルールを詰め込むほどAIの注意力は散漫になる。
さらに深刻なのがトークンの浪費だ。
最新の検証データが衝撃的な事実を突きつけている。
Claude Codeには4種類の設定ファイルがある。
それぞれのフロントマターで設定を記述できる。
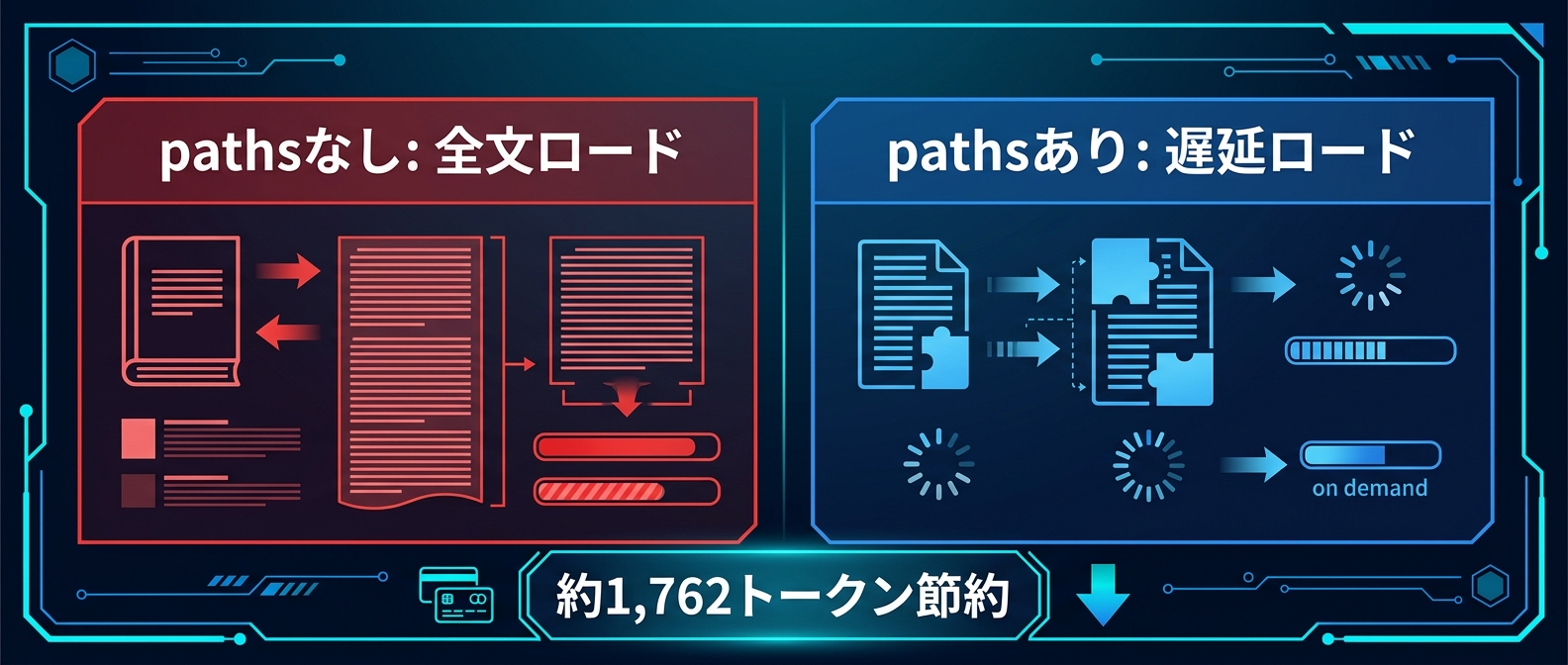
設定の有無でコンテキストへの読み込み方が変わる。
ルールのフロントマターでpathsを指定しない場合。
そのルールの本文はセッション開始時から常にコンテキストにロードされる。
paths指定ありの場合はロードされない。
pathsのみ指定の場合もロードされない。
説明文のみ指定の場合は全文ロードされる。
フロントマター全削除の場合も全文ロードされる。
1ファイルあたり約1,762トークンが消費される計算だ。
ルールファイルが10個あれば約1万7,000トークンを消費する。
これが毎回のプロンプト送信時に発生する。
APIの利用料金が跳ね上がる。
レスポンス速度も著しく低下する。
一方でエージェントやスキルの設定ファイルは挙動が異なる。
これらは説明文だけがロードされ、本文はロードされない。
1ファイルあたり約100トークンの消費に収まる。
agentsのフロントマターにはname、description、model、toolsなどを設定できる。
skillsのフロントマターにはname、description、disable-model-invocationなどを設定できる。
これらはdescriptionだけがコンテキストに載り、本文は載らない。
フロントマターを全削除してもディレクトリごと削除しても結果は同じだ。
エージェントやスキルの説明文はトークン節約の観点では影響が小さい。
説明文の本来の役割は、AIが適切なスキルを選ぶための判断材料だ。
説明文が曖昧だとAIが意図しないスキルを選んでしまう。
決定的に影響が大きいのはルールのpaths指定だ。
これがあるかないかでコンテキストの圧迫度が変わる。
Claude Codeでスキルを作る際、専用のコマンドを使うと便利だ。
スキル作成コマンドを実行すると、nameとdescriptionが自動でフロントマターに付与される。
一方で通常の方法で「スキル作って」と頼むと、フロントマターが付かないケースがある。
このフロントマターの有無がトークン消費に直結する。
VSCode拡張での挙動も検証されている。
skillsのフロントマターでpathsやmodelを設定すると警告が表示される。
公式ドキュメントでは13キーがサポートされているが、VSCode拡張では8キーしか認識されない。
逆にVSCode拡張が認識するcompatibilityやlicenseは公式ドキュメントに記載がない。
双方向で乖離が生じているため、設定時には仕様の差異を考慮する。
ルールを詰め込むとAIは混乱する。
トークンは消費される。
肝心な時にルールが破られる。
単一ファイルでのルール管理は破綻している。
しんたろー:
1ファイルで1,762トークンも消費するのか。
10ファイルで1万7,000トークンが毎回飛んでいく計算になる。
塵も積もれば山となるってレベルじゃないな。
多層アーキテクチャによるガードレール設計
解決策は多層的かつ文脈依存のガードレール設計だ。
ルールを分割して遅延ロードさせる。
具体的にはrulesディレクトリを活用する。
特定の言語やディレクトリに依存するルールは独立したファイルに切り出す。
ファイル先頭のフロントマターでpathsを指定する。
TypeScriptのコーディング規約をCLAUDE.mdに書くのは非効率だ。
Pythonのスクリプトを直している時にTypeScriptのルールを読ませる意味はない。
rulesディレクトリ内に専用のファイルを作る。
pathsに「src/*/.ts」と指定する。
AIが該当するファイルを開いた瞬間にルールがコンテキストにロードされる。
これが遅延ロードだ。
セッション開始時のトークン消費はゼロになる。
AIのコンテキストウィンドウは常にクリーンに保たれる。
不要な情報がないからハルシネーションも減少する。
さらにAIの暴走を防ぐ仕組みが求められる。
CLAUDE.mdの指示は長いセッションの中で忘れられる。
これを防ぐにはHooksを使った物理的な強制が必要になる。
ルールは3層で構成する。
1層目はCLAUDE.mdだ。
プロジェクトの概要や基本方針だけを書く。
グローバルな文脈を提供する層だ。
2層目はrulesディレクトリだ。
pathsを使って特定の対象ファイルのみにルールを適用する。
「設定ファイルを変更する時は確認する」といった文脈依存のルールだ。
必要な時だけコンテキストに介入する層だ。
3層目がHooksだ。
これが最も強力なガードレールになる。
PreToolUseフックなどを使い、ツール実行前に物理的に処理を一時停止させる。
「大きな声を出さないで」と貼り紙をするのがCLAUDE.mdとrulesだ。
「大きな声を出したらアラームを鳴らす」のがHooksだ。
AIがルールを忘れてもHooksが物理的に防いでくれる。
事故の教訓から生まれたOSSの汎用ガードレール集が存在する。
すべてのHookイベントをカバーした構成になっている。
Hooksには様々な発火タイミングがある。
SessionStartは新規セッション開始時に1回だけ発火する。
プロジェクト名や日付、基本的な行動指針をセッション冒頭に注入する。
Claude Codeのプロンプトキャッシュ機能は強力だ。
冒頭の固定テキストはキャッシュされてコストが下がる。
SessionStartフックはこの仕組みを活用する。
変化しない情報を冒頭に集中させることで、APIの利用料金を抑える。
UserPromptSubmitはユーザーが入力を送信するたびに発火する。
これがスマートなコンテキスト注入の核心だ。
入力プロンプトに「git push」や「rm -rf」などのキーワードが含まれているかを検知する。
検知した場合のみ、該当するルールファイルをコンテキストに注入する。
必要なときだけ必要なルールを注入し、精度とトークン効率を両立する。
PreToolUseはClaudeがツールを使用しようとする直前に発火する。
このHookの最大の特徴はNode.jsで書かれていることだ。
シェルスクリプトでは難しいJSON操作をNode.jsで行う。
Claude Codeがツール実行前に渡すツール入力パラメータをパースする。
再帰的削除コマンドや強制プッシュなどのリスクパターンを高精度に判定する。
Stopはセッション終了時や中断時に発火する。
未コミットの変更を検知して警告を出す。
Dockerビルド後の報告漏れなどを防ぐ最後の砦となる。
長時間かかるコマンドのタイムアウト対策も設定する。
Claude CodeのBashツールにはデフォルトで2分のタイムアウトがある。
これを知らずに重いビルドを走らせると中途半端な状態で処理が止まる。
環境固有の制約もルールとして明記しておく。
「npm installは時間がかかるからタイムアウトに注意しろ」と教える。
この3層が連動して堅牢なガードレールが完成する。
AIは文脈を理解し、必要な時だけルールを意識する。
万が一の暴走はシステムが食い止める。
これが現代のClaude Code運用のベストプラクティスだ。
単なるトークン節約術ではない。
AIを正確にコントロールするためのアーキテクチャだ。
環境変数の変更ルールがCLAUDE.mdに埋もれているプロジェクトは多そうだ。
AIが勝手にいじって本番環境が落ちるリスクを想像するとゾッとする。
物理的に止める仕組みの有無で安心感が全く違うな。

ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
実務への影響とディレクトリ構成の解体
プロジェクトのディレクトリ構成を見直す動きが広がっている。
CLAUDE.mdが肥大化しているなら解体作業を始める。
プロジェクト全体に関わる基本情報だけを残す。
「このプロジェクトは何を目指しているか」。
「どのようなアーキテクチャを採用しているか」。
これらはCLAUDE.mdに置く情報だ。
特定のファイルやディレクトリに依存するルールを抽出する。
それらをrulesディレクトリ内の個別のファイルに切り出す。
フロントエンドのコンポーネント規約。
バックエンドのAPI設計ルール。
データベースのマイグレーション手順。
設定ファイルの変更プロトコル。
これらはすべてpathsを指定して遅延ロードさせる。
「src/components/*/.tsx」のように適用範囲を明確に絞り込む。
曖昧な指定は過剰適用の原因になる。
破られてはいけないルールにはHooksを仕掛ける。
環境変数の変更。
Dockerコンテナの再ビルド。
本番データベースへの接続。
これらはAIに「確認して」とお願いするだけでは不十分だ。
スクリプトを書き、実行前に必ず人間の承認を求めるように物理的にロックする。
PreToolUseフックはNode.jsのプロセス環境変数を読み込む。
TOOL_INPUTやTOOL_NAMEといった変数を取得する。
JSON.parseを使って入力パラメータをオブジェクトに変換する。
リスクパターンと照合し、CRITICALやHIGHといったレベルで警告を出す。
ルールを適切に分割し、必要な時だけ呼び出す。
物理的なストッパーを用意する。
この設計で開発の安全性とスピードは向上する。
ただし、設定ファイルの記述ミスでHook自体が動かないという本末転倒な事態も起きる。
AIは優秀なアシスタントだが完璧ではない。
彼らが働きやすい環境を整え、暴走を防ぐ仕組みを作る。
トークンコストを抑えながら制御精度を高める。
Claude Codeを本格導入するなら多層ルール設計が前提となる。
エージェントやスキルの説明文の書き方も見直す。
トークン消費への影響は少ないが、AIの判断精度には直結する。
説明文が曖昧だとAIが意図しないスキルを選んでしまう。
手動でしか使わないスキルにはモデルの呼び出しを無効化する設定を付ける。
disable-model-invocationをtrueに設定すると、descriptionがコンテキストから消える。
これでAIの自動判断から除外できる。
トークン消費もゼロになる。
不要になったルールは捨てる。
「やらかし」から生まれたルールもプロジェクトが成熟すれば不要になる。
定期的にルールを棚卸しし、コンテキストを常に最適化する。
細部までコントロールを手放さない。
それがAI駆動開発を成功させる鍵だ。
複数の情報源から得られた統合知見として、ルールの階層化はさらに進化している。
ある実践設計ガイドでは、4層の階層設計が提唱されている。
CLAUDE.md、rulesディレクトリに加えて、Memoryシステムを組み込むアプローチだ。
MemoryシステムはClaudeが過去の文脈や決定事項を覚えておく仕組みだ。
セッションがリセットされても、重要な情報を引き継ぐことができる。
これにより、同じ指示を繰り返す手間が省ける。
グローバルルールとプロジェクトルールを分ける設計もある。
全プロジェクト共通のルールはホームディレクトリの「.claude」に配置する。
プロジェクト固有のルールはプロジェクトルートの「.claude」に配置する。
この2つを明確に分離することで、ルールの管理が容易になる。
「やらかし」から生まれたルールは具体的で効果が高い。
抽象的なルールから具体的なルールへと進化させていく。
効果的なルールは適用範囲を明確にし、禁止事項を具体的に記述している。
3層制御アーキテクチャの考え方は面白い。
CLAUDE.mdとrulesとHooksで役割を分ける発想はなかった。
どの層で何を制御するか、設計の腕の見せ所になりそうだ。

FAQ
Q1: Claude Codeでルールを書く際、CLAUDE.mdとrulesディレクトリのどちらを使いますか?
全体に関わる基本的な振る舞いやプロジェクトの概要はCLAUDE.mdに記述する。
特定の言語やディレクトリに依存するルールはrulesディレクトリに分割する。
TypeScriptのコーディング規約や設定ファイルの変更手順などがこれに該当する。
ルールを分割することでトークン消費を抑えつつ、必要な時だけAIにルールを意識させることが可能になる。
コンテキストの汚染を防ぐための基本戦略だ。
Q2: rulesファイルにpathsを指定しないとどうなりますか?
pathsを指定しない場合、そのルールの全文がセッション開始時から常にコンテキストにロードされる。
ファイル数が増えると数万トークンを消費することになる。
関係のない作業中にもルールが適用されてしまう。
AIの動作が不自然に止まるなどの過剰適用の原因になる。
コンテキストウィンドウを消費しないためにも、pathsで適用範囲を限定する。
Q3: AIがルールを無視して設定ファイルを勝手に上書きしてしまうのを防ぐには?
CLAUDE.mdの指示だけでは長いセッション中にAIがルールを忘れることがある。
確実な防止策として、rulesディレクトリで対象ファイル編集時の確認手順を明記する。
それに加えてClaude CodeのHooksを利用する。
PreToolUseフックなどで変更前に物理的に処理を一時停止させたり、バリデーションを走らせる。
CLAUDE.md、rulesディレクトリ、Hooksの3層制御でAIの暴走を封じ込めることができる。
まとめ
ルールの遅延ロードと物理的なストッパーでAIの暴走は防げる。
1ファイルあたり1,762トークンの浪費を止める設定を見直す。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
