
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
AIエージェントがインフラの限界を突破した日
Metaが発表した自律型システムが、AIモデルの推論スループットを60%向上させた。
人間の専門家が数週間かける最適化作業を、わずか数時間で完了させたのだ。
これは単なるツールアップデートではない。
AIエージェントの役割が「コード生成」から「ハードウェアの低レベル最適化」へと完全にシフトした瞬間だ。
インフラの複雑さをAIが自律的に解決する時代が来た。
僕らは今、ソフトウェアとハードウェアの境界がAIによって溶けていく歴史的な転換点に立っている。
3つの巨頭が描く「エージェントによるインフラ抽象化」の全貌
今、AI業界で全く異なる3つのアプローチが同時進行している。
それぞれの動きを追うと、次世代の開発アーキテクチャの輪郭がはっきりと見えてくる。
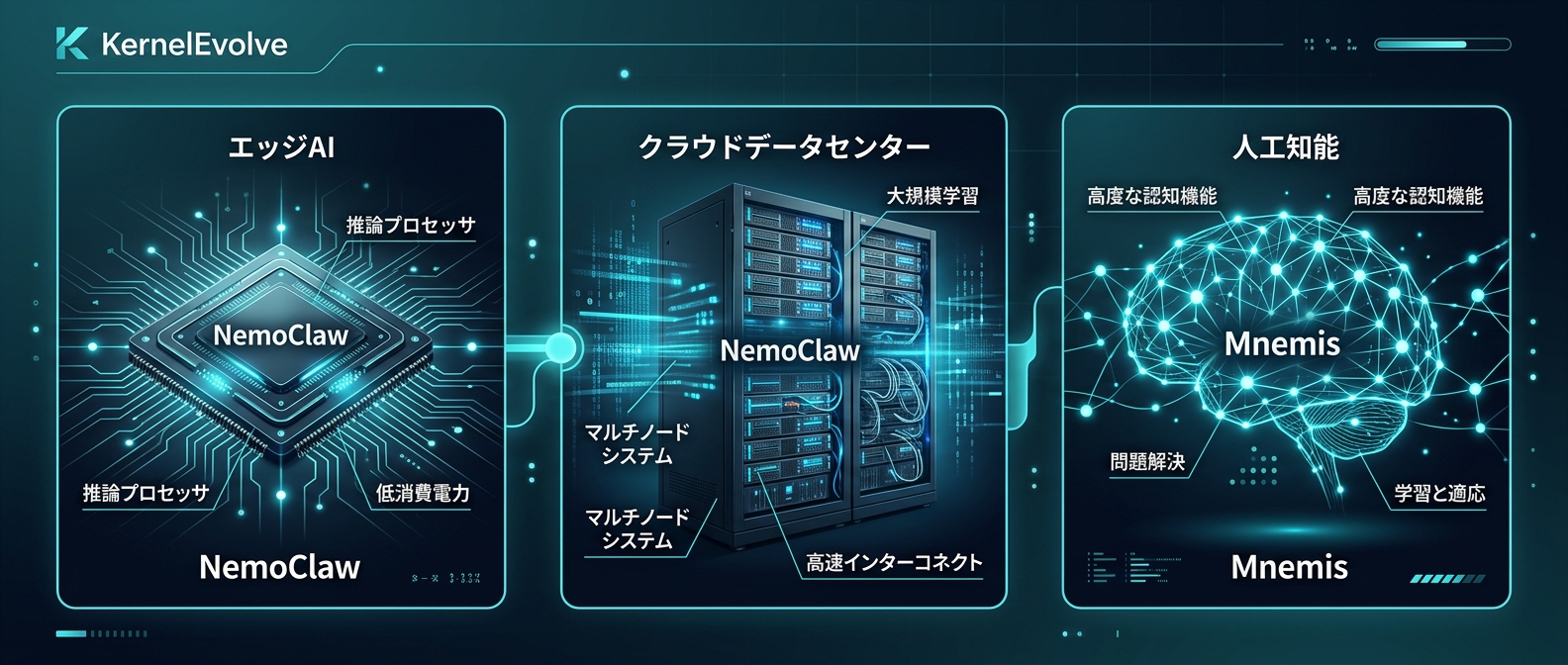
第一の動きは、Metaが発表したKernelEvolveだ。
これはハードウェアの低レベルなカーネル最適化を自律的に行うエージェントシステムである。
AIモデルが巨大化するにつれて、演算を効率的に処理する小さなプログラムの重要性が増している。
しかし、ハードウェアの種類が増え、数千もの構成を手作業でチューニングすることは不可能になっていた。
* 数百の代替実装を自律的に探索し、最適なコードを生成する。
* 人間の専門家が数週間かける作業を、わずか数時間で完了させる。
* 推論スループットを60%向上させ、数兆回の推論リクエストを処理する環境にデプロイされている。
* 特定のGPUだけでなく、カスタムシリコンやCPUなどあらゆるハードウェアに対応する。
第二の動きは、Nvidiaが発表したエンタープライズ向けエージェント基盤のNemoClawだ。
企業が安全にエージェントを動かすための標準プラットフォームとして設計されている。
企業がAIエージェントを導入する際の最大の壁は、セキュリティとガバナンスだ。
社内の機密データをAIにアクセスさせるリスクをどう管理するかが問われている。
* オープンソースの柔軟性と、エンタープライズの堅牢性を両立。
* 特定のハードウェアに依存しない、完全なハードウェア非依存の設計。
* ローカルデバイスからクラウドモデルまで、一つのコマンドでシームレスにアクセス可能。
* エージェントの挙動とデータ処理を完全に制御できるガバナンス機能を提供。
第三の動きは、Microsoftが提唱した長期記憶アーキテクチャのMnemisだ。
アプリケーション層におけるエージェントの記憶管理を根本から変える概念である。
これまでのエージェントは、過去の対話履歴をそのままコンテキストウィンドウに詰め込んでいた。
しかし、これではコンテキストの上限に達しやすく、コストも跳ね上がる。
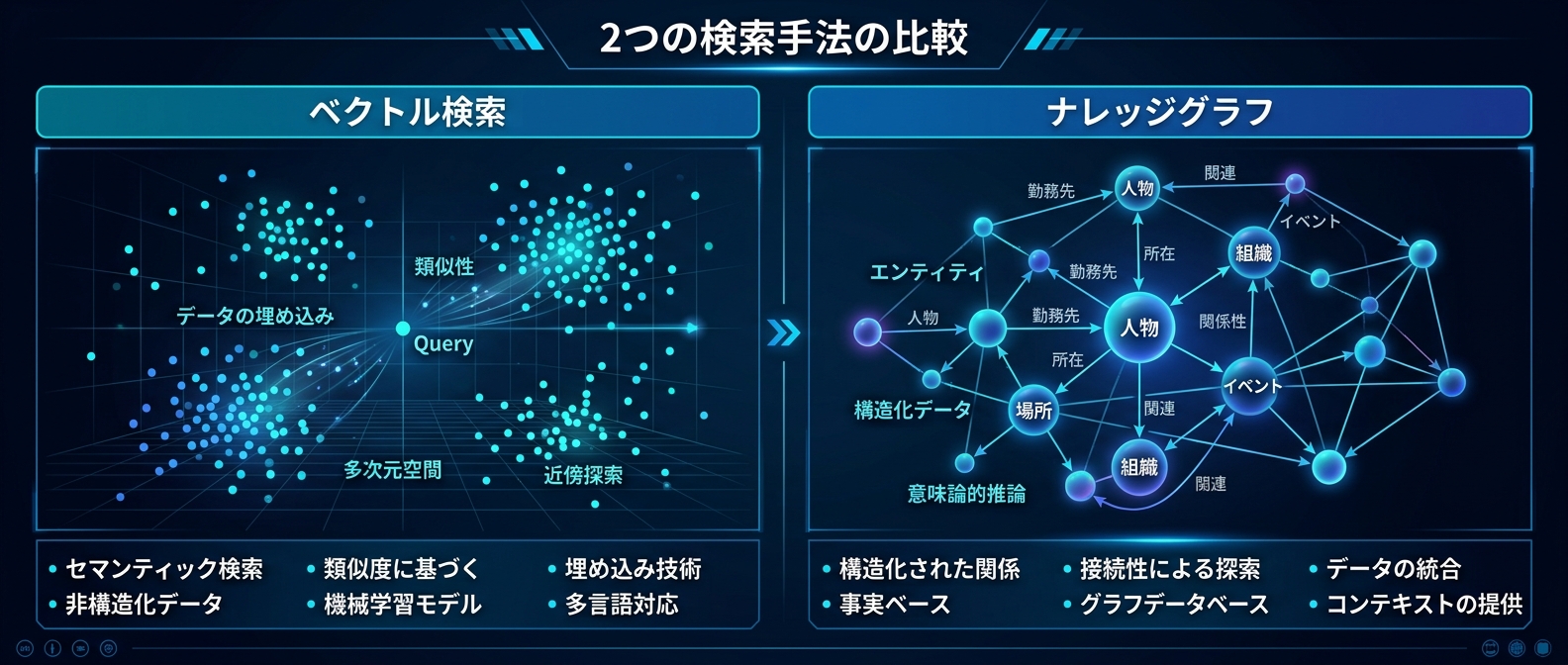
* 過去の対話履歴を単なるテキストではなく、ナレッジグラフとして構造化して保持する。
* 直感的な類似度検索と、論理的な関係性を辿る探索を組み合わせたハイブリッド検索を実現。
* 複雑な因果関係を正確に抽出し、AIの回答精度を飛躍的に高める。
* 抽出したエンティティや関係性を別々に評価し、最適なコンテキストを再構成する。
これら3つの事象は、一見バラバラに見える。
しかし、本質は「AIエージェントがシステム全体の複雑さを隠蔽し始めている」という一点に集約される。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
開発の常識が変わる。AIスタックの垂直拡大と複合システム化
ここからは開発者としての本音を話す。
AIエージェントの適用領域が、アプリケーション層からインフラ層へと垂直に拡大している。
これまでエージェントといえば、チャットUIや簡単なコード生成が主戦場だった。
それが今や、ハードウェアのカーネル最適化という最も泥臭い領域にまで入り込んでいる。
しんたろー:
ハードウェアの最適化をAIに丸投げできるのは本当にエグい。
これが一般化したら、インフラエンジニアの仕事の定義が根底から覆る。
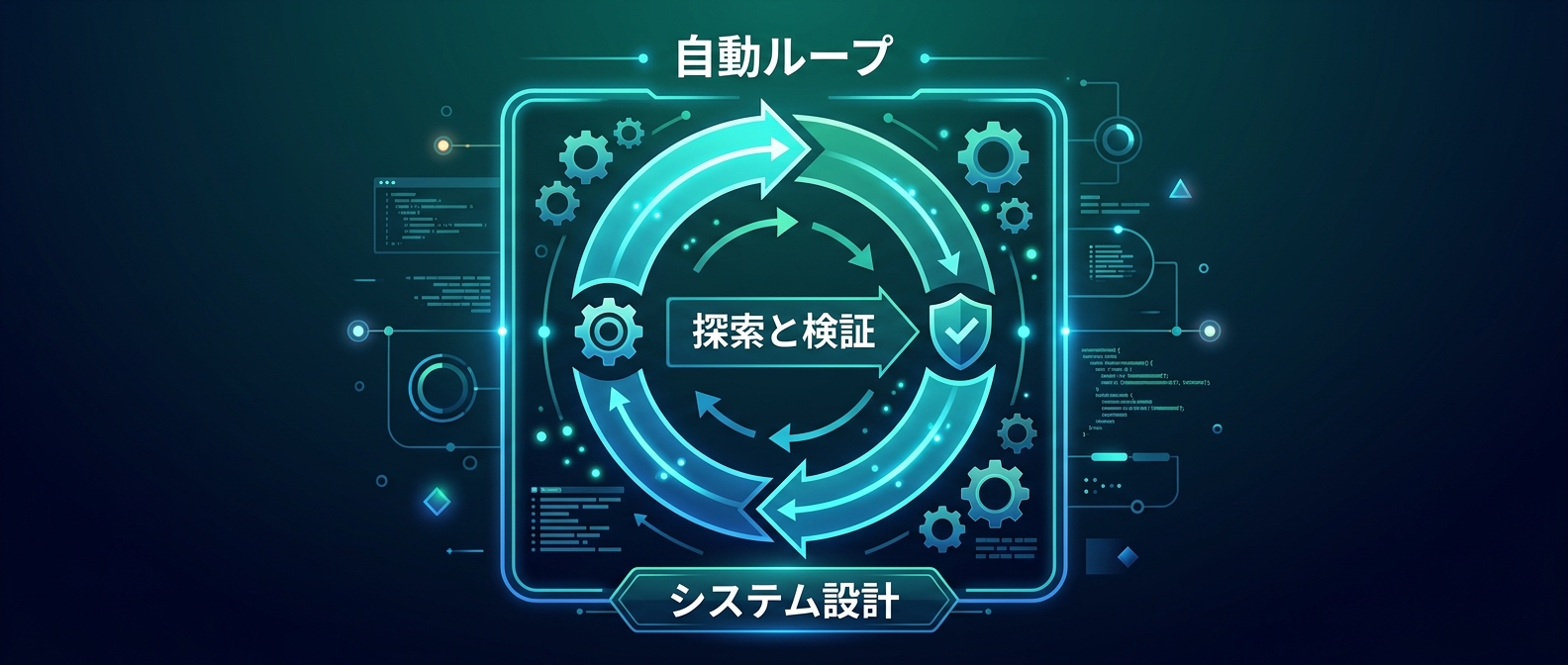
Metaのアプローチで最も面白いのは、カーネル最適化を「ワンショットのコード生成」ではなく「探索問題」として捉えた点だ。
LLMに一発で正解を書かせるのではなく、大量の候補を生成して検証するループを回している。
これは、単一プロンプトへの依存からの完全な脱却を意味する。
より人間に近い「推論と検証のサイクル」を、システム内部で高速に回しているのだ。
僕が普段使っているClaude Codeでも、この「探索と検証のループ」の片鱗を感じる。
単にコードを出力するだけでなく、エラーを検知して自律的に修正案を提示してくるからだ。
Nvidiaの動きも興味深い。
彼らはエージェントを動かすためのインフラ自体を標準化しようとしている。
Metaが「インフラ最適化のためにエージェントを使う」のに対し、Nvidiaは「エージェントのためのインフラを作る」アプローチだ。
ベクトルは逆だが、目指しているのは「ハードウェアの差異を意識させない世界」である。
これまでは、新しいハードウェアが出るたびに専門家が手作業でチューニングを行っていた。
GPUのメモリアクセスパターンやスレッドの割り当てなど、極めて低レベルな調整が必要だった。
しかし今後は、プラットフォーム側がエージェントを使って自動で最適化を完了させる。
開発者は、基盤となるハードウェアのアーキテクチャを深く理解する必要がなくなる。
抽象化のレイヤーが一段上がり、よりビジネスロジックの構築に集中できる環境が整いつつある。
これは開発者にとって圧倒的なアドバンテージだ。
さらに、Mnemisのようなグラフベースのメモリシステムが普及すれば、エージェントの文脈保持能力は劇的に向上する。
単純なベクトル検索では拾いきれない、複雑なエンティティ間の関係性をAIが理解できるようになる。
たとえば、「ユーザーが胃炎になった」という事実と「体重管理をしている」という事実。
これらを別々のベクトルとして扱うのではなく、因果関係を持つグラフとして繋ぎ合わせる。
Claude Codeで複雑なリファクタリングをさせると、たまにプロジェクト全体の文脈を見失うことがある。
グラフベースのメモリが統合されたら、この辺の弱点も一気に解消されそうだ。
エージェントの内部アーキテクチャは、確実に「複合システム化」へと向かっている。
探索アルゴリズムやハイブリッド検索など、複数のコンポーネントを組み合わせた設計がこれからの標準になる。
単一の巨大なプロンプトで全てを解決しようとするアプローチは、すでに時代遅れだ。
小さな専門エージェントが協調し、グラフデータベースや検証ツールと連動しながら動くシステムが主流になる。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
僕らのアーキテクチャ設計はどう変わるのか
で、このトレンドは僕らの日々の開発にどう影響するのか。
結論から言うと、エージェントを「単なるAPI」ではなく「自律的なコンポーネント」として扱う設計力が求められる。
まず、単純なRAGからの脱却を視野に入れるべきだ。
ベクトル検索だけで精度の高い回答を引き出すのは限界に来ている。
* ユーザーの過去の行動履歴をナレッジグラフとしてデータベースに格納する。
* テキストの類似性だけでなく、エンティティ間の論理的な関係性を辿れるようにする。
* これらを組み合わせたハイブリッド検索を実装し、コンテキストの質を高める。
* 検索結果をリランキングし、LLMに渡すプロンプトを最適化する。
次に、コード生成やインフラ設定の自動化において「探索ベース」のアプローチを取り入れることだ。
一発で完璧な出力を求めるのではなく、複数の候補を生成して自動テストで検証する仕組みを作る。
探索と検証の自動ループは、個人開発のスピードを爆上げするポテンシャルがある。
エラーハンドリングの自動化だけでも、精神的な負担が全然違う。
そして、ハードウェアの低レベルな最適化は、今後エージェントの仕事になる。
僕ら開発者は、複雑なメモリ管理アルゴリズムを自力で書く必要がなくなる。
その代わり、エージェントが正しく動作するための「制約」と「評価基準」を設計する能力が重要になる。
AIが生成したコードや設定が、ビジネス要件を満たしているかを判定するテストコードの価値が跳ね上がる。
* エージェントの出力結果を自動で評価するテストパイプラインの構築。
* システム全体のパフォーマンス指標の明確化。
* エージェントが暴走しないための安全なサンドボックス環境の用意。
* 予期せぬ動作を検知してロールバックする仕組みの実装。
システムアーキテクチャの設計において、エージェントはもはや外部のブラックボックスではない。
システムの一部として深く組み込まれ、データの流れを制御する中核コンポーネントになる。
これに伴い、僕ら開発者の役割は「コードを書く人」から「システムを設計し、エージェントを指揮する人」へとシフトする。
データモデリングの基礎体力が問われる領域だ。
また、非同期処理とイベント駆動アーキテクチャの重要性も増す。
探索ベースのエージェントは、結果を返すまでに時間がかかる。
ユーザーを待たせないUI/UXの工夫や、バックグラウンドでエージェントを走らせるインフラ設計が不可欠だ。
技術の進化に振り回されるのではなく、それを武器として使いこなす視点が求められている。
インフラの複雑さはAIによって隠蔽され、開発者はより上位のアーキテクチャ設計に集中できるようになる。
これが、これから数年で起きる開発パラダイムの決定的な変化だ。
AIを活用した開発基盤の構築は、もはや大企業だけの特権ではない。
オープンソースのツールや、APIとして提供されるエージェント基盤を組み合わせることで、個人開発者でも強力なシステムを構築できる。
次世代AIアーキテクチャに関するFAQ
ハードウェア最適化エージェントは一般の開発者も利用できる?
現時点では、特定の巨大企業の内部システムとしての発表に留まっている。
しかし、この「探索ベースのカーネル最適化」というアプローチは、将来的にオープンソースのフレームワークに統合される可能性が高い。
数年後には、僕らが普段使うコンパイラの一部として、意識せずに恩恵を受けられるようになるはずだ。
ハードウェアの知識がなくても、最高性能を引き出せる未来がすぐそこまで来ている。
エンタープライズ向けエージェント基盤は特定のGPUが必須?
いいえ、最新のプラットフォームは完全なハードウェア非依存として設計されている。
特定のメーカーのGPUだけでなく、ローカルのCPU環境やクラウド上のモデルにもシームレスにアクセスできる。
企業が既存のインフラ上で、ベンダーロックインを気にせずにエージェントを動かせる標準環境を目指している。
これにより、開発者はインフラの制約から解放され、エージェントのロジック構築に専念できる。
グラフベースのメモリは従来のベクトル検索を完全に置き換える?
完全に置き換えるのではなく、相互補完的な関係になる。
グラフ検索は「胃炎の原因が体重管理にある」といった複雑な因果関係を辿るのに優れている。
一方、単純な意味的類似性の検索にはベクトル検索が速くて有効だ。
実際のシステムでは、これらを組み合わせたハイブリッド検索とリランキングの構成が主流になる。
エージェントがインフラを飲み込む時代
AIエージェントはコードを書くだけでなく、インフラの最適化から記憶の構造化まで自律的に行うようになった。
この進化のスピードは、僕らの想像を遥かに超えている。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
