
画像判定が1回2円で終わる。
最新の巨大AIモデルに画像を投げれば、マニアックなバイクの車種すら一瞬で特定される。
単発のタスクなら、もうAIに丸投げでいい。
だが、複雑なドキュメント解析やシステム画面の操作になると話は別だ。
汎用モデルに丸投げした途端、処理は重くなり、コストは跳ね上がり、AIは画面の前でフリーズする。
単発の視覚タスクと、連続する状態タスク。
この境界線を見極めないと、開発したシステムは簡単に破綻する。
単発の画像認識タスクでは、モデル間の明確な性能差がある。
カタログ写真ならどのモデルも正解する。
しかし、スマートフォンで雑に撮影された写真になると結果は残酷だ。
あるモデルは5回中1回しか正解せず、別のモデルは無料枠の制限が厳しすぎて1回のリクエストでエラーを吐いた。
最終的に圧勝したのは、業界標準となっている巨大な汎用モデルだ。
斜めから撮られた写真でも正確に車種を特定し、そのコストは1回あたりわずか約0.01ドルから0.02ドル。
日本円にして約2円だ。
個人開発の予算でも、商用レベルの高精度な画像認識が完全に実用化されている。

一方で、複雑な構造を持つドキュメント解析の領域では、全く逆のアプローチが注目を集めている。
表や数式、図面が混在するビジネス文書の処理だ。
ここでも巨大な汎用モデルを使えば文字は読める。
しかし、大規模な生産環境やエッジデバイスで動かすには、モデルが重すぎて計算資源の無駄遣いになる。
そこで、10億パラメータ未満の軽量な特化型モデルを構築する動きが加速している。
単にページを左から右へ読むのではない。
まずレイアウト解析専用の軽量モデルで文書の構造を把握し、意味のある領域ごとに分割する。
その上で、並列処理によってテキストやデータを抽出する2段階のパイプラインだ。
さらに、1回の計算で複数のトークンを同時に予測する技術を導入し、処理スループットを約50パーセント向上させている。
力技の丸投げではなく、タスクの分割と特化による最適化が進んでいる。
そして最も壁が高いのが、AIによるUI操作だ。
AIエージェントにシステムの画面を見せて、自律的に操作させる技術領域である。
ここ数年でAIが画面上のボタンや入力欄を認識する能力は向上した。
しかし、実際の業務システムを安定して操作させるのは依然として極めて難しい。
その理由は、画像認識の精度不足ではない。
UIが本質的に持っている「状態」を、AIが理解できないからだ。
人間は画面の文脈や直前の操作から「今は入力途中だ」「これはエラー画面だ」と瞬時に判断する。
だがAIにとってUIは、単なるピクセルの集合体に過ぎない。
見えない状態や禁止ルールを推測できず、不適切なボタンを押して処理を破壊する。
有力なAI企業が、ソフトウェア内でのAIの視覚と操作に特化した専門チームを買収した事実も、この問題の根深さを物語っている。
しんたろー:
1回2円で高精度な画像判定ができるのは素直にすごい。
でもUI操作の話は耳が痛い。人間向けのきれいな画面ほど、AIにとっては意味不明なトラップだらけなんだよな。
Claude Codeにターミナル任せてるのとは次元が違う難しさだ。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
AIの視覚能力が分断した2つの領域
AIの視覚能力は、タスクの性質によって「丸投げできる領域」と「システム設計が必要な領域」に完全に分断された。
単発の対象認識は、もはや開発者が悩むフェーズではない。
ユーザーがアップロードした画像から特定の物体を検出したり、状態を判定したりする機能だ。
これは最新の巨大APIに画像を投げるだけで、人間と同等かそれ以上の結果が返ってくる。
開発者の仕事は、プロンプトを調整することと、APIのレスポンスをデータベースに保存することだけだ。
視覚のアルゴリズムを自前で組む時代は完全に終わった。
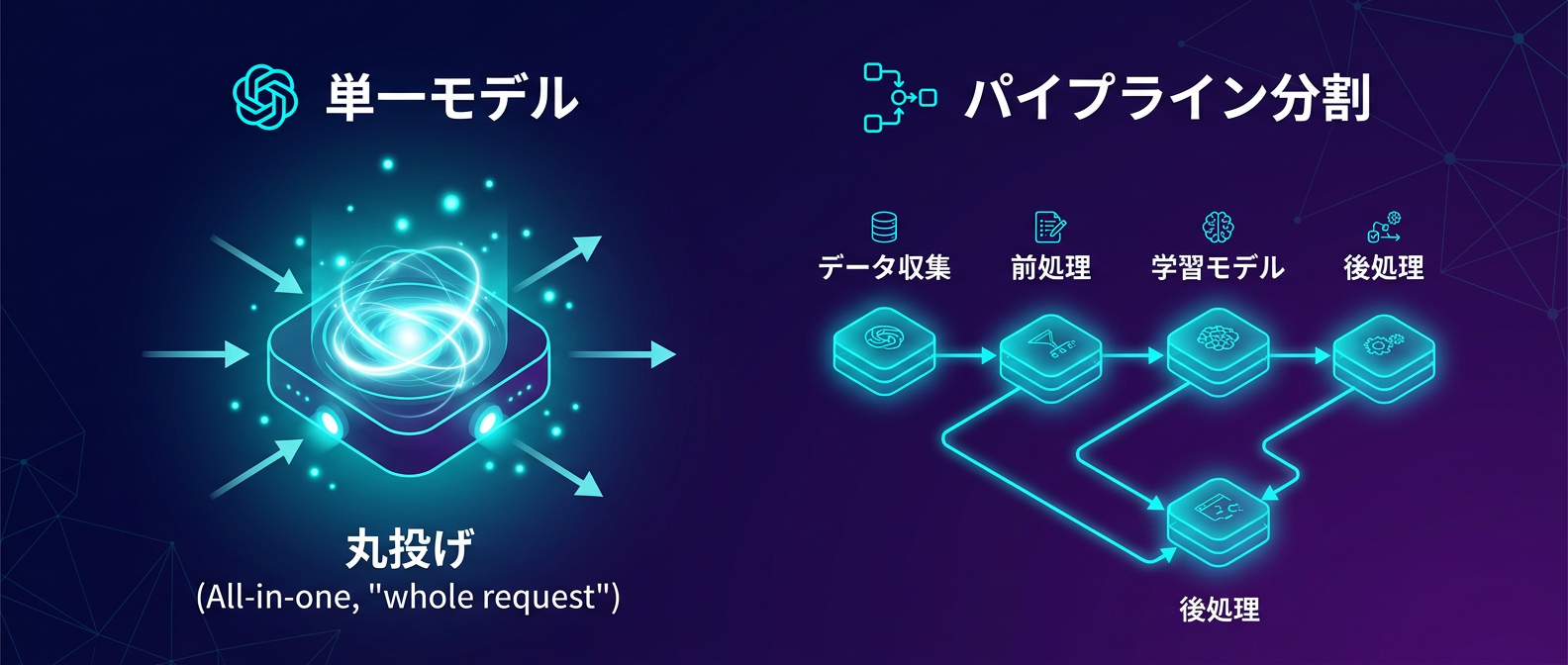
ドキュメント解析で汎用モデル丸投げが通用しない理由
しかし、コンテキストの理解が必要な領域では、汎用モデルへの丸投げは通用しない。
その代表例が、複雑なドキュメントの構造解析だ。
請求書や技術仕様書には、テキストだけでなく表や図解、注釈が複雑に絡み合っている。
これを1枚の画像として巨大モデルに投げ込むと、文字の書き起こしはできても、データの構造関係は高確率で崩れる。
だからこそ、最前線の開発ではパイプラインの分割が必須になっている。
レイアウトを解析するモデルと、領域ごとに文字を認識するモデルを分ける。
このアプローチなら、巨大モデルに依存せずとも、軽量で高速な特化型モデルの組み合わせで高精度なJSONデータを出力できる。
AIの能力を引き出すのは、単一の賢いモデルではなく、開発者が設計する処理のアーキテクチャだ。
AIエージェントがUIを壊す本当の理由
さらに深刻なのが、AIエージェントによるUI操作の領域だ。
僕たちは普段、UIを見た目のデザインとして捉えている。
しかしシステム設計の観点から見れば、UIとは「状態機械の表面」に過ぎない。
同じ「送信」ボタンでも、必須項目が未入力の時と、通信待機中の時では、背後にある状態が全く異なる。
人間は画面のわずかな色の変化や、これまでの操作履歴から、その見えない状態を無意識に補完している。
AIにはその無意識の補完ができない。
AIに自社のSaaSや社内システムを操作させようとする時、多くの開発者は「画面のスクリーンショット」と「操作マニュアル」をAIに渡そうとする。
これは完全に悪手だ。
マニュアルには正常系の順番しか書かれていない。
通信エラーが起きた時や、予期せぬポップアップが出た時の「状態の定義」が抜け落ちている。
AIは画面上にボタンを見つけると、現在の状態がそれを許容しているかどうかにかかわらず、クリックを試みる。
結果として、データの不整合やシステムのクラッシュを引き起こす。
AIがソフトウェアの画面を見て自律的に行動する技術は、単なる画像認識の延長ではない。
視覚情報とシステム状態を同期させる、全く新しいインタラクションの課題だ。
最近のAIは目が良くなったと錯覚しがち。
でも実際は「写真に何が写ってるか」が分かるだけで、「このシステムが今どういう状態か」を理解してるわけじゃない。
見た目だけを読ませる設計は、遅かれ早かれ事故る。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
タスクに応じた使い分けが開発者の腕の見せどころ
汎用モデルの進化は凄まじい。
だが、それは「何でも1つのモデルで解決できる」ことを意味しない。
むしろ、モデルが多様化し、タスクに応じた使い分けが求められるようになった。
単発の画像判定には、最も賢い汎用巨大モデルを1回2円で使い捨てる。
大量のドキュメント処理には、専用にチューニングされた軽量モデルを組み合わせてスループットを稼ぐ。
そしてAIエージェントとの連携には、AIが迷わないための専用のインターフェース設計を用意する。
今日から使える3つの実装パターン
では、日々の開発にどう落とし込むか。
まず直面するのが、強力なAPIを組み込む際の「モデルの陳腐化」への対策だ。
画像認識に使うAIモデルの名前は、数ヶ月単位で頻繁に変更される。
半年前に動いていたコードが、突然「このモデルは非推奨です」というエラーとともに沈黙する。
対策はシンプルだが強力だ。
APIリクエスト時のモデル名を、ソースコードの中に直接書き込んではいけない。
必ず環境変数や外部の設定ファイルに切り出す。
これだけで、モデルの世代交代が起きた時も、コードの再デプロイなしで設定値を書き換えるだけで対応できる。

次に、ドキュメント解析やデータ抽出機能を実装する場合の設計方針だ。
ユーザーがアップロードしたPDFや画像からデータを抜く機能は、SaaSの定番だ。
ここで、とりあえず最新の巨大モデルに画像を投げてJSONを要求するアプローチは、プロトタイプまでにしておく。
実運用に入ると、処理の遅さとコストの高さが確実にネックになる。
実務でスケールさせるなら、まずは安価なレイアウト解析ツールや軽量なOCRモデルで文書の構造を特定する。
そして、本当に高度な推論が必要な箇所にだけ、巨大モデルのAPIをピンポイントで呼び出す。
このハイブリッドなパイプライン設計が、ランニングコストを大幅に下げる。
そして3つ目が、今後確実に普及する「AIエージェントによる自動操作」を見据えたシステム設計だ。
Claude Codeのような優秀なエージェントに開発やテストを支援させる時、この壁にすでに直面している。
AIに自社のシステムを操作させるなら、人間向けの美しいUIだけを提供してはいけない。
AIが必要としているのは、システムの「現在の状態」だ。
今は初期表示なのか、入力途中なのか、エラーから復帰した直後なのか。
どの操作が許可されていて、どの操作が禁止されているのか。
これらの状態や遷移条件を、画面の見た目とは別に、メタデータやログ、専用のエンドポイントとして明示的に出力する。
「状態の外部化」と呼ばれるこの設計思想を取り入れるだけで、AIエージェントの動作安定性は大きく向上する。
モデル名を環境変数に出すのは基本中の基本。
でも「状態の外部化」は盲点だった。うちの構成でも、AI向けにステートをJSONで吐き出す専用のデバッグモードを用意したほうが、エージェントのテスト自動化が捗りそうだ。
まとめ:設計力がプロダクトの競争力を決める
AIの視覚能力は、単なる機能から、システムアーキテクチャの前提条件へと変わった。
何でもかんでもAIに丸投げするフェーズは終わった。
開発者がシステムの構造を整理し、AIが働きやすい環境を整える。
その設計力が、これからのプロダクトの競争力を決定づける。
FAQ
Q1: 画像認識APIを使う際、モデルのアップデートによるコード破壊を防ぐには?
AIモデルの名称は数ヶ月サイクルで変更され、古いモデルはすぐに非推奨になる。
APIリクエスト時のモデル名をソースコードにハードコードするのは厳禁だ。
必ず環境変数や設定ファイルに切り出して管理する。
プロバイダー側でモデルの廃止や新バージョンのリリースがあった際も、コードを修正・デプロイすることなく、設定値の変更のみで即座に対応できる。
Q2: ドキュメントのOCRやデータ抽出に最新の巨大モデルを使えば十分ですか?
単純なテキスト抽出や単発の処理なら十分機能する。
しかし、複雑な表やレイアウトを含む文書を大量に処理する場合、精度・コスト・処理速度のすべてが課題になる。
実務では、事前にレイアウトを解析して領域ごとに分割するパイプラインを組むか、用途に特化した軽量モデルを組み合わせるアプローチが有効だ。
すべてを巨大モデルに丸投げせず、適材適所でタスクを分割することがコスト最適化の鍵になる。
Q3: AIエージェントに自社システムのUIを操作させるには何が必要ですか?
画面の見た目を提供するだけでは不十分だ。
AIは「現在の状態(入力途中、エラー発生中など)」や「禁止されている操作」を画面の文脈から推測するのが非常に苦手だ。
AIを安全に動作させるには、現在のシステム状態や遷移可能な条件を、メタデータや構造化データとして明示的に提供する「状態の外部化」設計が必要になる。
人間向けのUIとは別に、AIが状態を正確に把握できるインターフェースを用意する。
AIの視覚能力は圧倒的だが、システムの状態や構造の理解まで丸投げできる魔法ではない。
タスクを分割し、AIが迷わないように状態を明示する設計力が、これからの開発者の最大の武器になる。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る

ThreadPost 代表 / SNS自動化の研究者
ThreadPost運営。Claude Codeで1人SaaS開発しながら、海外AI最新情報を開発者目線で発信中。
@shintaro_campon関連記事

Google公式発表。Gemini 3.1 ProでAI開発はどう変わるのか。単なるチャットボットから脱却する理由

【2026年版】最新AIエージェント構築ツール3選|1人SaaS開発者が本気で比較

Anthropic公式が発表。DeepSeek等にClaudeが1600万回不正抽出された理由とAI開発への影響

【2026年版】最新AIエージェント比較3選|1人SaaS開発者が推す最強環境

【2026年版】Cursorで実現するAI駆動開発Tips10選|1人SaaS実践者が厳選

【2026年版】ChatGPT・Gemini画像生成AI5選|1人開発者が実務で使う
人気の記事

【2026年覇権交代】1億4,150万人が選ぶ「最強テキストSNS」と2つの高反応時間帯

エンゲージメント2倍!7100万件のデータから導くベスト投稿時間3つの法則

月収18万で廃業寸前だった大学中退フリーランスが「対象を絞っただけ」のメルマガ配信ツールで年商60億円を創った裏側

巨大企業の歯車として消耗していた2人の会社員が『ただの要望掲示板』を作ったら年商4.5億円。

1回25ドルのトークン消費。Claude Codeのマルチエージェント化が迫る、個人開発のハイブリッド運用。
