
SNS運用を自動化しませんか?
ThreadPostなら、投稿作成・画像生成・スケジュール管理まで全てAIにお任せ。
冒頭フック
LLMに計算を任せるとプロジェクトが死ぬ。
請求書の合計金額を出させる。
RAGで「3万円以下」を検索させる。
結果は惨敗だ。
AIは意味を理解する天才だが、足し算はポンコツだ。
開発者が直面する「LLMの限界」と、それを乗り越えるための評価基盤の話をする。
LLMアプリ開発が直面する「計算と検索」の壁
生成AIを実務に組み込むと、必ず壁にぶつかる。
紙の請求書からデータを抽出するOCRシステム。
100を超えるフォーマットが存在する。
LLMに「ガソリン代の合計を計算して」と指示を出す。
別の行の数値を拾う。
灯油の金額まで足してしまう。
計算ミスが多発する。
特定の読み取り間違いを直すためにプロンプトを修正する。
指示が複雑になり、レスポンスが長くなる。
結果として全体の精度が低下する。
そこでファインチューニングを試す。
JSONL形式の学習データを作成する。
画像に回転やノイズ追加のデータ拡張を施し、モデルをチューニングする。
特定のパターンには効果が出た。
しかし、別の請求書では間違いが直らない。
100以上のフォーマット全てに汎化させるのは不可能だった。
この検証に1ヶ月を溶かすことになる。
RAGを使ったテーブルデータの検索も同じだ。
製品カタログから「重量が2kg以下」「価格が3万円以下」の製品を探す。
キーワード検索のBM25は全く機能しない。
「最も軽い製品」というクエリに対し、Recall@5のスコアは0.00だ。
抽象的な表現と「重量1.5kg」という具体値を結びつけるのは単語一致では不可能だ。
ベクトル検索のDense検索も数値の比較には苦戦する。
AIは意味解釈のプロだが、決定論的な処理は全くできない。
※この記事は、Claude Codeで1人SaaS開発しているしんたろーが、海外AI最新情報を開発者目線で解説する「AI活用Tips」です。
役割分担と評価基盤の構築
LLM単体で全てを解決しようとするアプローチは限界を迎えている。
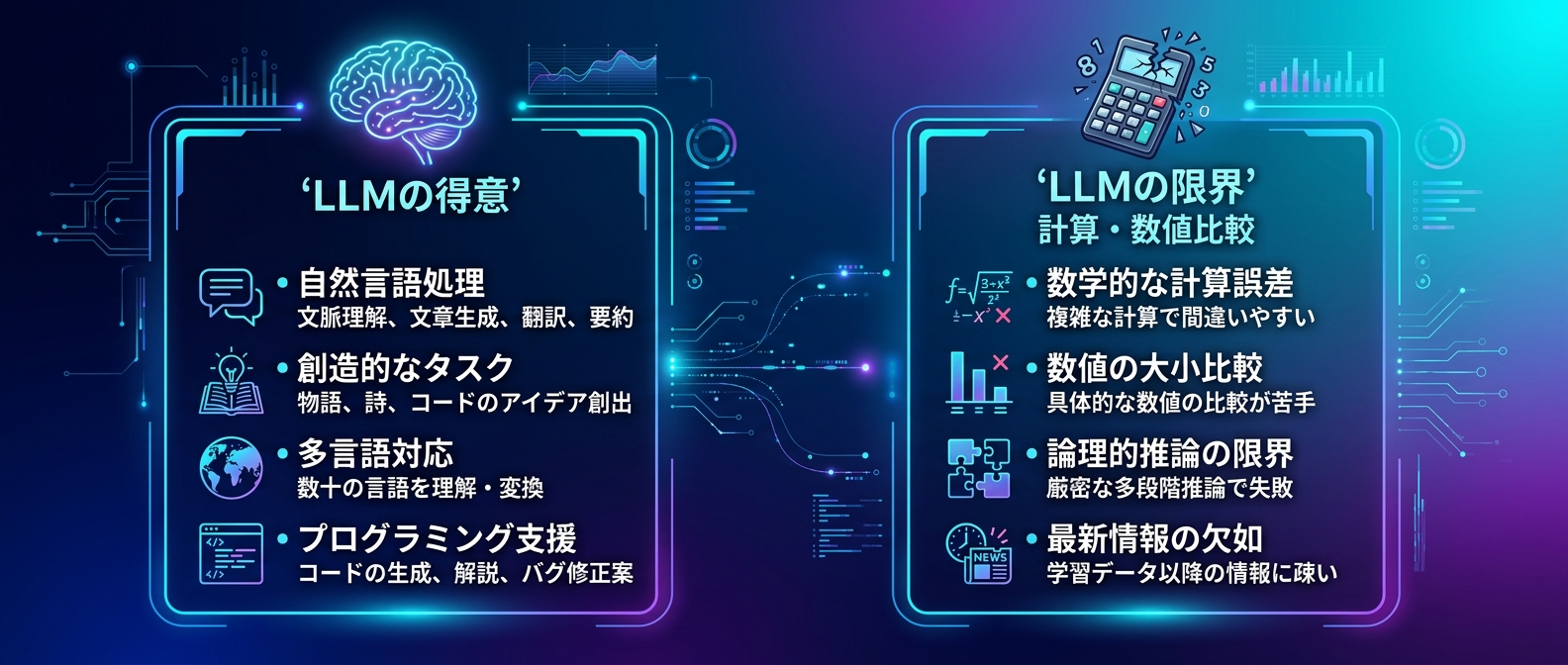
解決策は「役割分担」だ。
LLMにはテキストからの項目抽出だけを任せる。
抽出した数値データの合計計算は、サーバーサイドのプログラムで処理する。
RAGの検索も同じだ。
ベクトル検索で候補を絞り込み、最終的な数値条件のフィルタリングはデータベースのクエリに委譲する。
これが実務における最適解だ。
RAGに食わせるデータ形式も重要になる。
人間にとって見やすい「Markdownの表形式」は、AIには不親切だ。
パイプ記号やハイフンがノイズになる。
Embeddingモデルの意味表現の精度を下げてしまう。
最も検索精度が高かったのは、自然言語の「説明文形式」だ。
「この製品は重量2.5kgで、価格は45000円です」と文章にする。
複合的な条件で検索される場合、自然文の文脈があることでAIが意味を豊かに捉えやすくなる。
しんたろー:
Markdownの表をそのままRAGに突っ込むの、初期はよくやってた。
パイプ記号がノイズになるって言われると確かに納得できる。
データの事前処理は地味だけど一番効く。
もう一つの大きな壁が「プロンプト変更によるデグレ」だ。
あるパターンのエラーを直すために「税込金額を優先」とプロンプトに追記する。
すると、税抜金額しか記載のない別の請求書が読み取れなくなる。
「あちらを立てればこちらが立たず」の地獄が始まる。
これを防ぐには、継続的な評価・トレース基盤の構築が必須になる。
最低でも数百件規模の「固定評価用データセット」を用意する。
プロンプトやモデルを変更するたびに、自動で正解率をテストする回帰テストの仕組みだ。
モデルのバージョンアップは正解率に大きく影響する。
プロンプトを変えなくても、モデルを変えるだけで精度が改善することがある。
逆に、今まで読めていたものが読めなくなることもある。
だからこそ、モデル変更時にも評価プログラムを回す必要がある。
さらに一歩進めるなら、LangfuseのようなLLMオブザーバビリティツールの導入が視野に入る。
本番環境での入出力のトレース。
データセットに基づく定量的な評価。
プロンプトのバージョン管理。
これらをシステム化し、安全な継続的改善を可能にする。
インフラ構築も課題になる。
Langfuseをクラウドで使うのも手だが、データプライバシーやコストの観点からセルフホストの需要も高い。
公式のTerraformモジュールは大規模向けでオーバースペックになりがちだ。
そこでAWSのECS Fargateベースでシンプルに構築する。
Kubernetesのクラスター管理は不要になる。
コンテナのオーケストレーションをマネージドサービスに任せる。
ClickHouseへの接続にはAWS Cloud Mapを使用する。
タスク再起動時も自動で内部DNSが更新される。
プライベートサブネットからのアクセスにはVPC Endpointを使う。
これでNAT Gatewayの月額固定費約45ドルを削減できる。
さらに、タスクやデータベースにARM64のGravitonプロセッサを採用する。
これで約20%のコスト削減が見込める。
Langfuseのセルフホスト構成、AWSのマネージドサービスで固めるのは綺麗だ。
Gravitonプロセッサでコスト削るあたり、実務の匂いがしてすごく良い。
うちのインフラ構築でも参考にしたい。
ここまで読んだあなたに
今なら無料で全機能をお試しいただけます。設定後は完全放置でプロ品質の投稿を毎日生成。
決定論的処理の切り出しとLLMOpsの実践
僕らの開発で今すぐ見直すべきポイントは明確だ。
LLMに「計算」や「数値の絞り込み」を任せている機能があれば、即座にアーキテクチャを変更する。
決定論的な処理はコード側に切り出す。
LLMは「非構造化データから構造化データを抽出するインターフェース」として割り切る。
これがシステムを安定させる唯一の道だ。
実務に落とし込むための具体的なアクションは以下の通りだ。
* LLMからの計算処理の完全な剥離
* プロンプトの簡素化と抽出特化
* サーバーサイドでの集計ロジックの実装
* RAGデータの前処理パイプラインの構築
* Markdown表から自然文への自動変換処理
* 数百件規模の固定データセットの作成
* CI/CDパイプラインへの評価スクリプトの組み込み
* Langfuseによる本番トレースの開始
* Claude Codeを活用したTerraformコードの生成
RAGの構築においても、データの持ち方を変える。
表形式のデータは、前処理の段階で自然文の「説明文形式」に変換してからベクトルデータベースに格納する。
これで検索精度は目に見えて変わる。
そして最も重要なのが、評価基盤の構築だ。
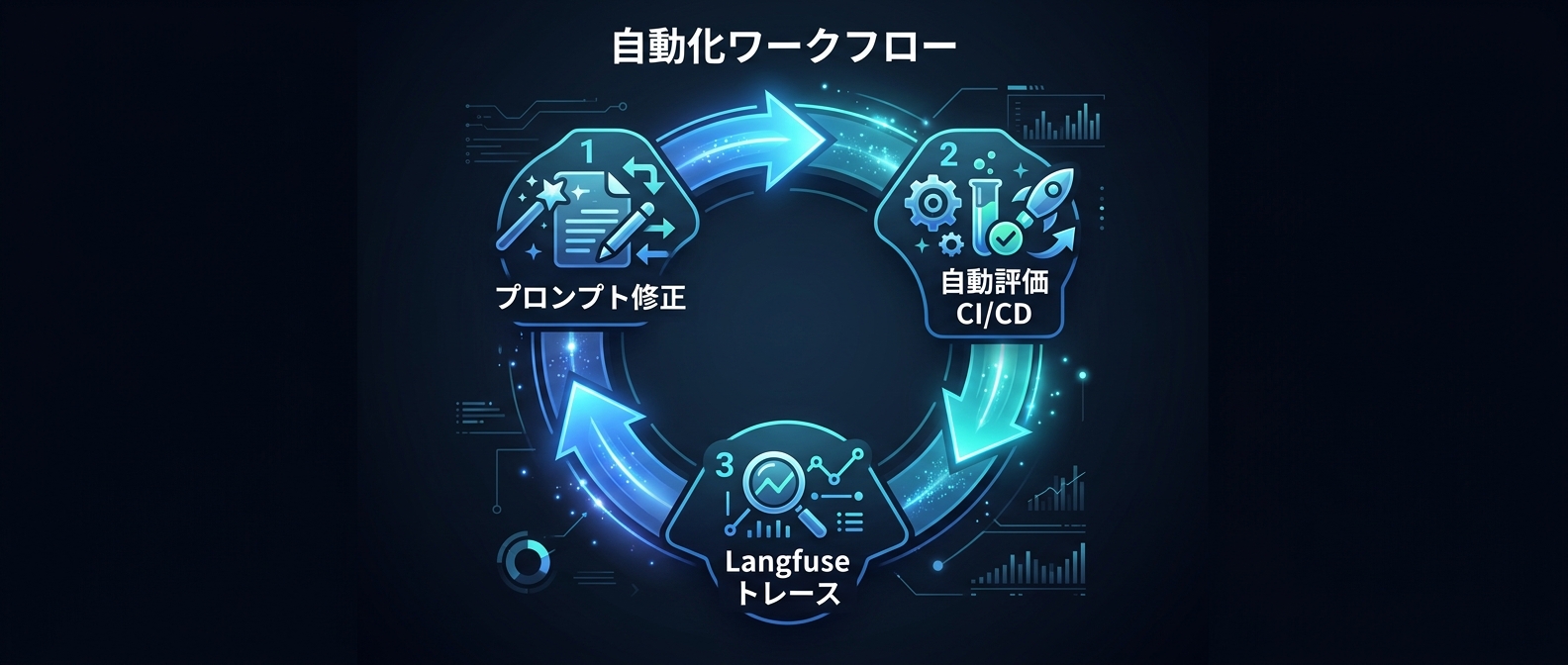
プロンプトの微修正が思わぬデグレを引き起こす。
開発の初期段階から、固定データセットによる自動評価CI/CDを組み込む。
1つのバグを直すたびに、数百件の評価を回す。
他に影響がないことを確かめてから次に進む。
一方を直すともう一方が壊れる場合は、トータルの正解率が高くなる方を優先する。
そういう割り切った判断も必要になる。
評価用スクリプトの作成や、Langfuseを動かすためのTerraformコードの記述。
こうした手間のかかる周辺タスクは、Claude CodeなどのAIコーディングエージェントに任せる。
インフラ構築やテストコードの生成は、AIが最も得意とする領域だ。
開発者は、本質的なプロンプトの改善やアーキテクチャの設計に集中する。
これが現代のLLMアプリ開発のスタンダードだ。
Claude CodeにTerraform書かせるのは本当に楽。
インフラのコード化は人間がゼロから書く時代じゃない。
評価スクリプトの自動生成もClaudeに任せれば一瞬で終わる。
よくある質問(FAQ)
Q1: LLMに表データや請求書の計算をさせると、なぜ精度が落ちるのですか?
LLMは本質的に「確率的に次の単語を予測するテキスト生成器」だ。決定論的な算術計算や厳密な数値比較を根本的に苦手としている。請求書から合計金額を計算させると、別の行の数値を拾うなどのミスが多発する。テーブルRAGの検証でも、「3万円以下」といった数値条件の検索においてベクトル検索の精度は低い。LLMには「テキストからの項目抽出や意味解釈」のみを行わせる。抽出された数値データの合計計算やフィルタリング処理は、サーバーサイドのプログラムやDBのクエリに任せる「役割分担」が実務のベストプラクティスだ。
Q2: プロンプトを改善したら別のケースで精度が落ちました。どう対策すべきですか?
「あちらを立てればこちらが立たず」というデグレは、LLMアプリ開発の典型的な罠だ。対策として、最低でも数百件規模の「固定評価用データセット」を用意する。プロンプトやモデルを変更するたびに自動で正解率をテストする回帰テストの構築が不可欠だ。さらに一歩進んで、LangfuseのようなLLMオブザーバビリティツールを導入する。本番環境での入出力のトレースや、データセットに基づく定量的な評価、プロンプトのバージョン管理をシステム化する。これで安全な継続的改善が可能になる。
Q3: テーブルデータをRAGで検索させる場合、どのようなデータ形式が最適ですか?
人間にとって見やすい「Markdownの表形式」は、LLMのEmbeddingモデルにとっては最適ではない。パイプ記号やハイフンなどの構造記号がノイズとなり、意味表現の精度を下げてしまう。検証で最も検索精度が高かったのは、表の内容を「〇〇は重量2.5kgで、価格は45000円です」のように自然言語の「説明文形式」に変換したデータだ。特に複合的な条件で検索される場合、自然文の文脈があることでAIが意味を豊かに捉えやすくなる。前処理で自然文に変換する工夫が極めて有効だ。
振り返り
LLMに計算を任せる幻想を捨て、評価基盤を構築した者だけが本番運用の壁を越えられる。

この記事が参考になったら、ThreadPostを試してみませんか?
投稿作成・画像生成・スケジュール管理まで、全てAIにお任せできます。
ThreadPostをもっと知る
関連記事

【2026年版】AIエージェントのコストを半減させる運用術12選|Claude Code開発の実践知

なぜClaude Codeはコード生成よりデータの構造化が重要なのか。自律エージェントの推論精度を高める開発者向け完全ガイド

なぜCursorとLangGraphでAI開発が激変するのか。エージェント自律化の最新潮流

【2026年版】Claude Code活用術10選|開発フローを自動化する最強スキル集

Claude Codeの自律操作で開発が変わる理由|思考プロセスをコード化する実践的アプローチ
